
MoE(Mixture of Experts)是一種「專家混合」架構。這就像一個團隊中有不同的專家,各自擅長不同領域的問題。當有問題需要解決時,系統會只叫出需要的專家來處理,而不是讓整個團隊都參與,從而節省大量資源。
在 Threads 上看到有網友提到一個新名詞,我沒看過,所以特別來研究一下。網友提到的 DeepSeek V3 也是一種大型語言模型(Large Language Model, LLM),但它在訓練過程中採用了 MoE(Mixture of Experts)架構,這是一種與傳統大型語言模型不同的設計與訓練方式。
DeepSeek V3 的設計目的是處理類似 GPT-4o 的自然語言任務,例如生成圖表、摘要文章、回答問題,它的模型架構和能力也符合大型語言模型的定義,例如支援多種語言、高效處理複雜任務等等。
而今天的問題是,在中國這家公司所表發的 DeepSeek V3,為什麼可以在「低算力」的環境下產出類似 Open AI 的產品?
View on Threads
大型語言模型怎麼訓練的?
在訓練這些「大腦」(也就是 LLM)時,我們需要教它怎麼去解決問題,我們以製造一個厲害的機器人為例子:
GPT-4o 的訓練方式
想像你有一個超級機器人,每次訓練它的時候,你要讓它的所有零件一起運作,這樣它才能變得更聰明,雖然它變得很厲害,但訓練它需要用到非常強大的電腦(就像很貴的 GPU),而且花很多時間和錢。
DeepSeek V3 的訓練方式
DeepSeek V3 的訓練方式有點不一樣,它用了一種叫 MoE(專家混合) 的技巧,這就像製作了很多小機器人,但它可以組成大機器人,而每個小機器人都是不同的「專家」,有的專注於語言,有的專注於數字,有的專注於故事。
你就當作百獸王合體之後的樣子……什麼?你童年沒聽過百獸王?
而當要去訓練 DeepSeek V3 時,只會啟動幾個需要的「小機器人」來完成當前的任務,其他的「小機器人」可以休息,整體就能節省很多資源。
為什麼這麼做比較好呢?因為這樣不需要用很貴的電腦(像更便宜的 H800 GPU),也能把 DeepSeek V3 訓練得很厲害,甚至有時候表現比 GPT-4o 還好。
總結訓練的過程:
- GPT-4o 的方式:讓機器人所有「零件」一起運作,學習速度快,但很費力。
- DeepSeek V3 的方式:只讓需要的「機器人」工作,其他機器人休息,學習效率也很高,但省了很多錢和資源。
而這種設計有幾個明顯的好處,由於只啟動部分專家,所以計算效率更高,特別適合大型語言模型,而且這種架構還可以根據任務的不同,動態啟用適合的專家模組,從而針對特定任務有更好的表現,特別是在硬體資源有限的情況下,MoE 架構可以讓模型在硬體需求較低的情況下,達到接近大型語言模型的效能。
MoE 是一種「偷吃步」的方式?
模型架構的「選擇性」運行
MoE 的核心特性在於它會根據輸入數據的特徵,動態選擇部分專家參與運算,而不是讓所有專家都同時運作,這種設計雖然大幅減少了計算量,但也讓人產生疑問:
- 它沒有真正運用全模型的能力,只是挑選「少數」專家參與工作,可能被認為是對資源的「妥協」。
- 相較於傳統的密集模型,MoE 的性能提升是否只是在「規模假象」下的效果,而非真正架構上的創新?
訓練和推理的非一致性
在訓練階段,MoE 會根據不同的數據路徑動態分配專家,這種隨機且情境依賴的選擇,可能會導致推理時出現不穩定的狀況:
- 推理過程中,因為選用的專家數量和具體專家可能隨著情境而變動,最終結果就顯得「三心二意」。
- 因此,有人認為這種做法其實是依賴「捷徑式推理」,而不是對輸入數據進行全盤考慮。
最佳化和協同的難度
MoE 的稀疏特性雖然有效節省了計算,但也引出了不少問題:
- 在訓練過程中,因為專家之間分工不均,梯度容易不穩定,需要額外依靠門控機制等最佳化技巧來平衡。
- 同時,不同專家之間缺乏足夠協作,讓模型在應對複雜任務時,表現反而可能不如預期。
對密集模型的依賴
MoE 其實並不是一個獨立、萬能的技術,它仍然依賴於底層的密集模型來提供基礎能力。這讓人覺得:
- MoE 更像是一種「加強式套件」,而不是從根本上解決問題的方案。
- 帶來的效果,實際上更多源自於那個不可或缺的密集模型,而非 MoE 自身的魔法。
目前測試起來還不錯
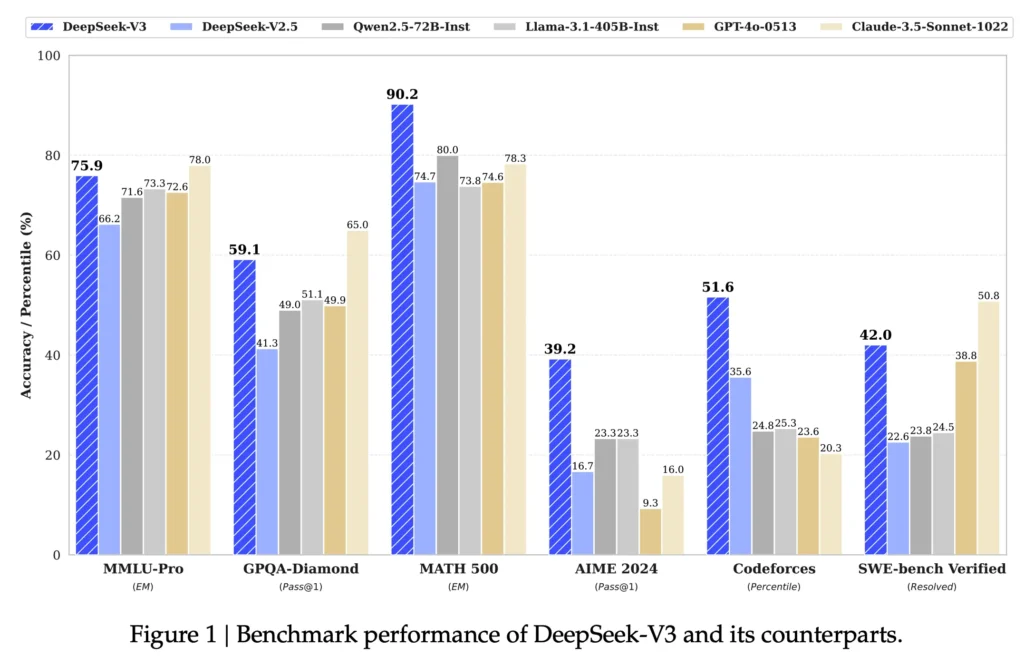
從DeepSeek-V3 Technical Report裡來看,在第一頁就有 DeepSeek-V3 與不同模型之間的測試比較,我先簡單介紹一下這些模型:
DeepSeek-V2.5
- 是 DeepSeek-V3 的前一個版本,用於對比改進效果。
Qwen2.5-72B-Inst
- Qwen 系列模型,參數量為 72B,主要是通義千問是由阿里開發出來的大型語言模型
Llama-3.1-405B-Inst
- Llama 系列模型,具有較大參數量,Meta的大型語言模型,常用於對比先進的開源模型表現。
GPT-4o-0513
- OpenAI 的 GPT-4 系列,這是其中的特定版本,用來作為高性能閉源模型的對比對象。
Claude-3.5-Sonnet-1022
- Claude 系列模型,由 Anthropic 開發,用於展示不同設計思路的模型在多任務上的表現。
MMLU-Pro 和 MATH 500 測試主要評估模型在多任務學習與數學推理中的準確性。DeepSeek-V3 在這兩項中表現良好,特別是在 MATH 500 測試中,以 90.2% 的高分顯著領先其他模型,展現了卓越的數學推理能力。而在 MMLU-Pro 測試中,DeepSeek-V3 的得分為 75.9%,稍低於 Claude-3.5 的 78%,兩者差距並不明顯。
GPQA-Diamond 和 AIME 2024 測試則主要考驗模型的問答準確性與語言理解能力。在 GPQA-Diamond 測試中,DeepSeek-V3 以 59.1% 的成績明顯領先 GPT-4o(49.9%),展現了強大的事實問答能力。而在 AIME 2024 測試中,DeepSeek-V3 再次以 39.2% 的得分在所有模型中排名第一,證明其在高難度推理問題上的卓越表現。
Codeforces 和 SWE-bench Verified 測試著重於模型在程式碼生成與軟體工程相關問題上的能力。DeepSeek-V3 在 Codeforces 測試中取得 51.6%,領先其他對手,充分展現了其程式碼生成能力。然而,在 SWE-bench Verified 測試中,DeepSeek-V3 的得分為 42.0%,稍遜於 Claude-3.5(50.8%),顯示其在軟體工程相關問題解決上的表現仍有進步空間。
總體來看,DeepSeek-V3 在數學推理(MATH 500)與程式碼生成(Codeforces)相關任務中展現了顯著的優勢,並在高難度問答(AIME 2024)中表現不錯。
然而,在 SWE-bench Verified 的軟體工程測試中,其表現稍低於 Claude-3.5,這表明在專業工程應用上仍有提升潛力。
MoE 的五大特色
選擇性啟動參數
DeepSeek 的模型裡有 6710 億個參數,但每次只會啟用 370 億個,其他就先休息。這就像一個擁有上千位專家的團隊,系統只會叫需要的專家來處理事情,讓效率大大提升,不浪費資源。
Multi-Head Latent Attention (MLA)
DeepSeek 用 MLA 技術來壓縮和重複利用重要資訊,減少記憶體的使用量。這就像整理筆記,把重點內容濃縮在幾頁內,後面要查找時就更方便、不會拖累系統運作。
FP8 混合精度訓練
DeepSeek 在處理運算時,用的是 8 位元(FP8)格式,這樣可以提升運算速度和降低記憶體需求。但遇到需要高精度的地方(像輸出結果)還是會用更高精度的格式,確保不出錯。這很像切水果時用普通刀具,雕花時則用專業雕花刀來提高精準度。
共享專家與路由專家
- 共享專家:負責處理日常的基本任務。
- 專家中的專家:遇到特殊或複雜的問題時才會啟動的專家,專門解決進階難題。
這樣的架構讓系統既能處理一般問題,又能應付需要專業知識的情境。
動態負載均衡
如果某個專家接的任務太多,系統會自動降低新任務分配給他的機率,把工作轉交給其他專家分擔。這就像交通管理系統,會調整車流方向,避免某條道路塞車,確保系統整體順暢運行。
如果你想試試 DeepSeek 現在就可以去玩看看,目前我的感受是「它的回應速度好快」,但也許是在線使用人數很少,所以才會有這種速度。
參考文章與文獻
規模假象是什麼?
你擁有一個超大的玩具箱,裡面有數不清的玩具,但每次你只拿出幾個來玩,看起來你有很多玩具(大規模),但實際上只玩了其中一小部分,這就是規模假象的意思。
不同的數據路徑動態分配專家是什麼?
想像你有一個團隊,每個成員都擅長不同的事情,有一天,學校出現了各種不同的問題:有的是數學問題,有的是語文問題,也有可能是自然問題,學校會根據每個問題的內容,自動把問題交給最合適的老師(也就是專家)來解決。
這個自動挑選老師的過程,就是「不同的數據路徑動態分配專家」的意思:根據每個問題的需要,立刻派出最厲害、最適合的人來幫忙,讓每個問題都能快速又正確地解決。
稀疏特性是什麼?
稀疏特性就像是一大群朋友,但每次只叫其中幾個來幫忙,而不是全部都出動,這樣既節省力氣,也讓工作做得更快。
門控機制是什麼?
想像你家門口有個警衛,只有認識你的人才能進來,門控機制就像那位警衛,只讓重要的資料進去工作,不需要的就讓它停在外面,這樣可以讓計算變得更快、更有秩序。
MLA是什麼?
想像你有本厚厚的書,裡面有太多細節,看起來會讓你眼花撩亂。於是,我們先挑出書中最重要的幾頁,做個簡單摘要,再請幾個人從不同角度看這幾頁,各自發現重點。
這就像 Multi-Head Latent Attention 先把大量資訊濃縮成重點,再用多個視角一起理解,既省時又能抓住精華。
FP8 混合精度
FP8 混合精度指在模型訓練中,部分運算用8位元浮點數(FP8)來加速和節省記憶體,而對精度要求較高的部分仍使用較高精度數據,這樣既兼顧效率,也能保持計算準確性。
精度又是指什麼?
精度指的是數據或計算結果的準確性,高精度意味著用更多數字來表示一個數值,使結果更接近真實值,低精度則可能帶來較大的誤差。
FP8 混合精度還是看不懂?
想像你在玩馬力歐賽車,有些 3D 畫面的計算不需要太精確,就像遊戲中的背景畫面,可以用比較簡單的方式(FP8,8位元浮點數)來加速處理,讓整個遊戲跑得更順暢,而公主人物造型要非常精美,細節要做到髮絲飄動、光影細緻,那就需要用更高精度的計算方式,例如FP32(32位元浮點數),因為它能處理更細微的數據,確保畫面不會有模糊或錯誤的細節。
所以,FP8 和 FP32 就像是「低解析度 vs. 高解析度」,該用高精度的地方就用 FP32,該節省運算資源的地方就用 FP8,這就是FP8 混合精度的概念!
要深入了解 AI 產品經理的基本職責和角色,請參考我的詳細指南:AI 產品經理,我的學習方法