總有些事情你不願再提,或有些人你不願再見。因為那些事或那些人,帶來的傷害你不想再被提起,更不想讓它們被翻出來討論。這就像有些資料,你絕對不想上傳到雲端,被別人看見,哪怕只是意外的可能。我懂,這些事有它的重量,也有它的價值。用本地的 LLM,其實就像給自己建了一座牢固的保險庫,所有的秘密都鎖在裡面,別人再也沒有機會碰觸。你儘管放心,無論是不可見的傷痕,還是那些需要深埋的資料,這一切,只有你能掌控。
以上文字改編自東邪西毒電影台詞。
Ollama 跑起來之前的基礎說明
Ollama 是什麼?
Ollama 就像是一個超方便的管理員,專門幫你在自己的電腦上運行那些很厲害的大型語言模型(像 AI 聊天機器人那樣的東西)。但跟一般需要上網登入的chatGPT 不一樣,Ollama 是設計給本地運行用的,也就是說,你可以完全在自己的電腦上跑這些模型,所有資料都不會被傳到網路上,安全又私密。
Ollama 支援很多不同的開源模型,比如 Llama 3、Phi 3、Mistral,還能在 macOS、Linux 和 Windows 上用。所以,不管你用什麼系統,只要電腦夠強,Ollama 都能幫你在本地跑起來,讓你用自己的 AI 工具。
Open Web UI 是什麼?
想像一下,Open Web UI 就像是一個超直覺的網頁工具,讓你可以輕鬆跟一個超聰明的 AI 模型聊天或測試它的能力。而且它是離線運作的,也就是說,你不需要把任何資料傳到網路上,一切都可以在你自己的電腦裡完成。這對於那些不想把隱私洩露出去的人來說,超級安全。
簡單講,你不用寫什麼指令,就可以讓你和下載回來的模型互動。
舉個例子,假設你下載了一個 AI 模型,但不知道怎麼用它。Open Web UI 就是幫你處理這一切的平台,你只要點幾下滑鼠、輸入問題,它就會幫你跟 AI 模型互動,非常方便。
Docker 是什麼?
你有一個程式,它需要一堆工具或特定的環境來運作,但這些工具可能在不同的電腦上很難設定,或者版本不相容。Docker 就能把這個程式和它所需要的所有工具(像作業系統、程式庫等)打包成一個「容器」。
這個容器就像一個獨立的小空間,裡面什麼都有,讓你的程式可以不受外部環境影響正常運行。這個容器很輕、很方便,拿到哪裡都可以用,在 Windows、macOS 或 Linux 系統上都能跑得很好。
舉例:如果你想運行 Open Web UI,Docker 就幫你把所有技術細節(像伺服器環境、模型檔案等)都包裝好。你不需要手動安裝複雜的依賴程式,也不用擔心你的電腦系統是否符合要求,只要能運行 Docker 容器,就能讓 Open Web UI 順利工作(還是希望電腦效能越高越好啦)。
但 2026 年開始跑 Ollama 不用再安裝 Docker 了
我們可以把 Docker 想像成「行動餐車」,把 Ollama 想像成「連鎖快餐店」。
以前跑 AI 模型就像是要開一家餐廳,你要自己買瓦斯爐、切菜板、排煙機(這就是安裝 Python、驅動程式、各種套件),過程非常麻煩。
為什麼以前要用 Docker?(行動餐車)
因為每台電腦的環境都不一樣(有的缺瓦斯、有的沒插座)。為了讓 AI 能在任何地方跑,工程師就把所有的廚具、食材全部裝進一台「行動餐車」(也就是 Docker 容器)裡面。
優點:只要有空地(也就是安裝了 Docker 的電腦),餐車停進去就能開賣。
缺點:餐車很重、發動很慢,而且要在餐車裡隔著窗戶把菜傳出來(這會產生效能損耗),還要處理餐車跟空地之間的電力接引(需要手動設定 GPU 權限)。
為什麼現在 Ollama 不用 Docker 了?(連鎖快餐店)
新版的 Ollama 就像一家「自動化快餐店」,它不再需要那台笨重的餐車。
- 它把所有工具都裝進「一個檔案」裡: 以前你要裝 Python、裝顯卡驅動、裝一堆有的沒的。現在 Ollama 把這些全部「濃縮」成一個簡單的安裝檔。你點兩下安裝,它就把所有廚具都帶齊了,不用再依賴 Docker 幫它運送環境。
- 它會自動跟你的顯卡「打招呼」: 以前用 Docker,你要寫一堆複雜的指令告訴 Docker:准許這台餐車使用我電腦裡的顯卡資源。現在的原生版 Ollama 變聰明了,它啟動時會自己檢查你的電腦是用哪種顯卡或晶片,並自動切換成最快的方式去運作,完全不用你動手設定。
- 直接住在你的系統裡,溝通更快: 因為它直接跑在你的 Windows 或 Mac 上,不需要隔著 Docker 那層餐車外殼,所以它讀取資料和回覆問題的速度,都變得像打開記事本一樣快。
總結來說:
- Docker 版:像是在電腦裡模擬一個環境給 AI 住,比較笨重。
- 現在的 Ollama:像是 AI 專門為了你的電腦量身打造了一套制服,穿上就能跑,更省空間、反應更快、安裝也更簡單。
用 Ollama 跑本地模型的前置需求
- Ollama 安裝
- 下載並安裝 Ollama 工具,詳情參考官方文件:Ollama 官方網站
- 硬體需求
- 以下步驟僅供Mac使用者參考。
- 強烈建議有一張支持 CUDA 的 GPU(如 NVIDIA 顯卡),以加速模型推理。
- 最好是用 Apple M 系列處理器。
安裝 Ollama 步驟教學
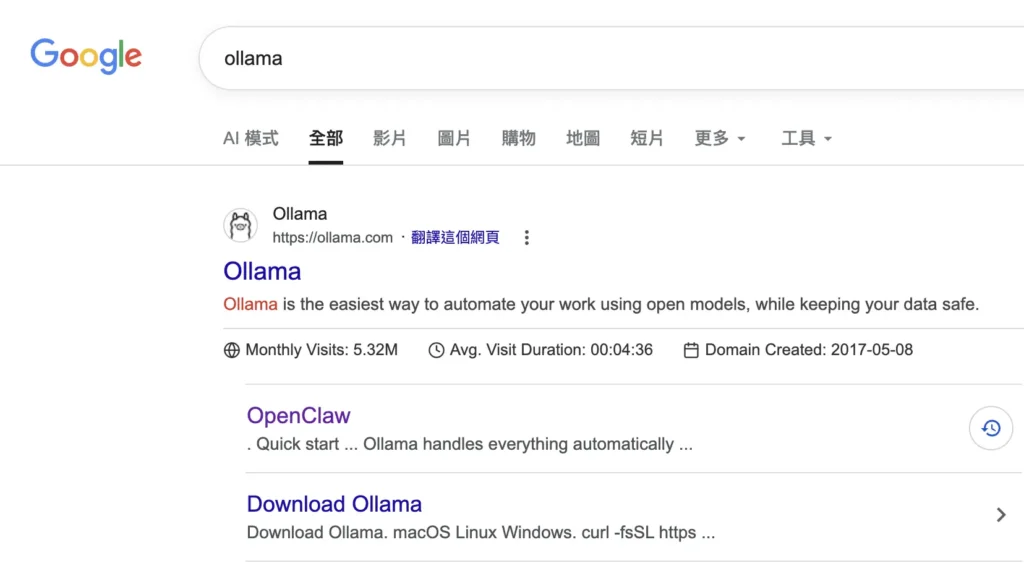
第 1 步驟:搜尋 Ollama
阿嬤!我們先去 Google 首頁這裡蛤,點擊「ollama」就好了!
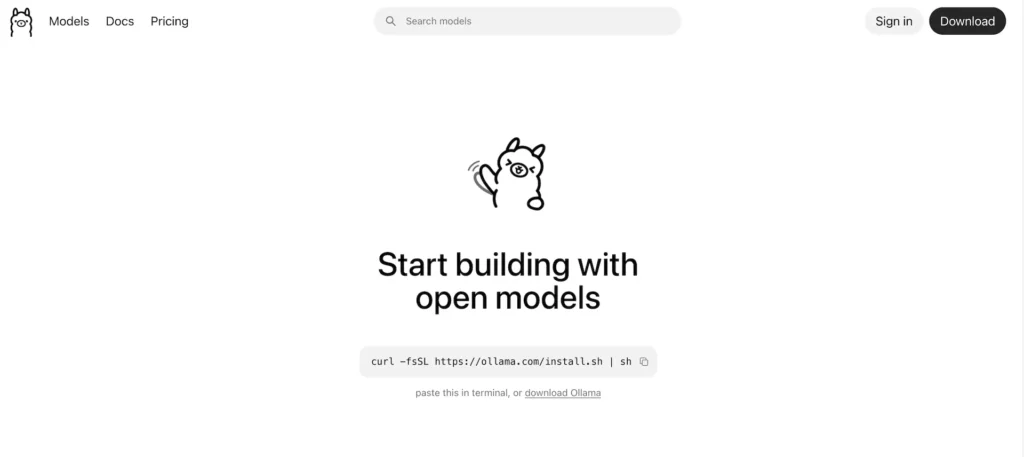
第 2 步驟:進入 Ollama 首頁
阿嬤!你應該有點擊「ollama」吧?接下來會進來下面這個 ollama 首頁哦!然後點擊「download Ollama」這行字。
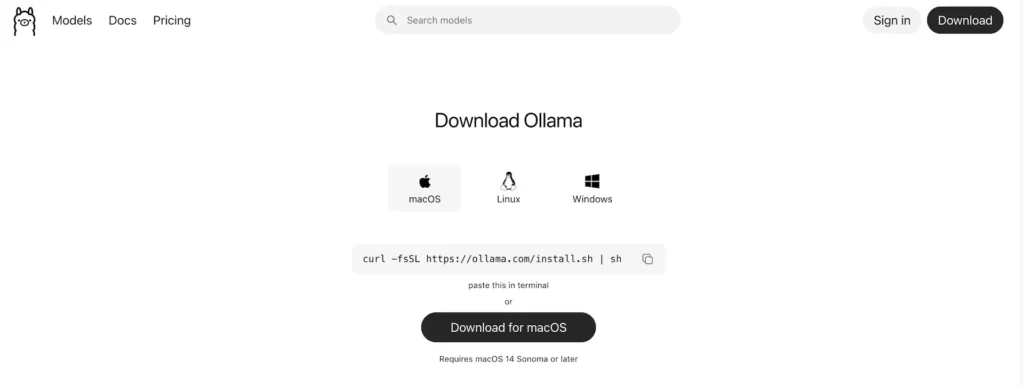
第 3 步驟:下載 Ollama
阿嬤,這頁的意思是問妳,你的電腦是哪一種系統啦!啊妳孫子/孫女應該是買MacBook Pro 16 M5 頂規的電腦給妳吧?接下來,妳點擊「Download for macOS」就好。
第 4 步驟:儲存 Ollama
然後,妳的 MacBook Pro 16 M5 電腦上會跳出一個畫面,它是要問你這個 ollama 檔案儲存在哪裡,我們選擇放在「桌面」就好了。
第 5 步驟:點擊 Ollama.dmg 安裝檔
妳的 MacBook Pro 16 M5 電腦就會出現 ollama.dmg 檔案,妳點擊兩下就可以了。
第 6 步驟:拉著 Ollama 放到應用程式資料夾
接下來,妳會看到畫面上彈出這個畫面,不要擔心,接下來,妳只要用滑鼠,把圖片中那隻看起來像羊的動物,拉進用程式資料夾就可以了。
第 7 步驟:開啟應用程式
然後啊,在你的 MacBook Pro 16 M5 電腦下方,應該有一個叫做「應用程式」的圖,你點一下,然後就會出現這個畫面了。

第 8 步驟:macOS 安全性警示彈窗
阿嬤接下來不要害怕,妳的頂級 MacBook Pro 16 M5 會跳出一個視窗,問妳要不要真的打開這個檔案,妳就用滑鼠點擊「打開」就好。
第 9 步驟:聊天對話視窗出現!
阿嬤!恭喜妳!妳裝好了!好棒棒~
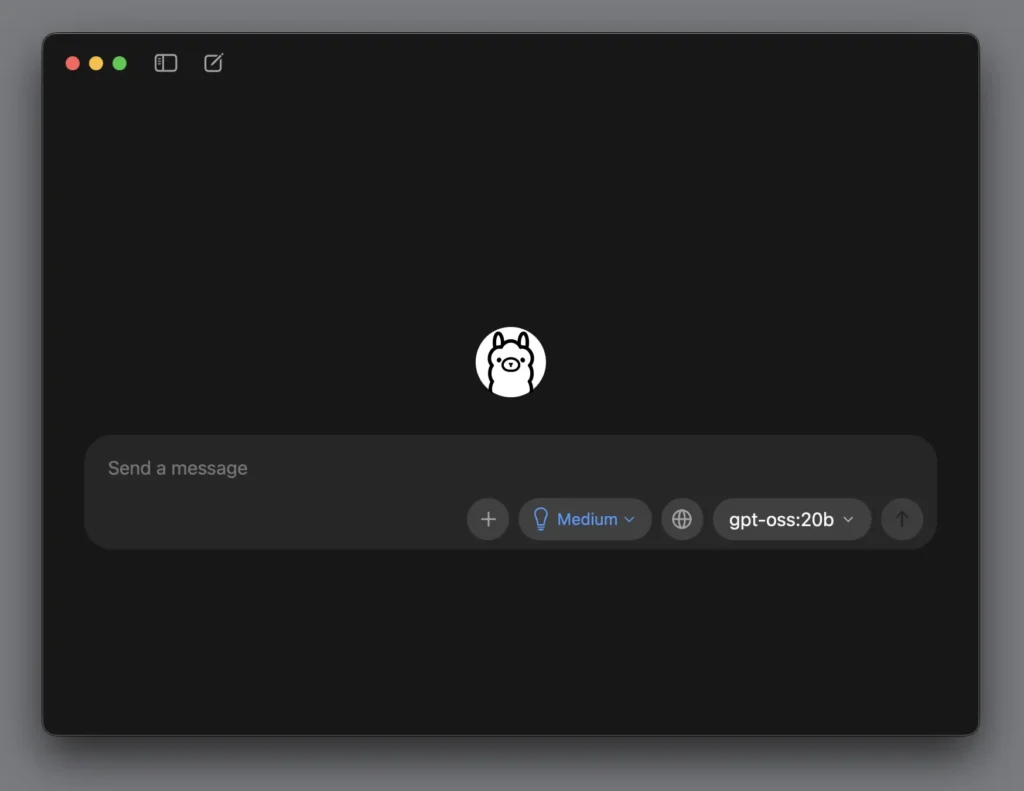
選擇 Ollama 裡的模型教學
選擇雲端模型
阿嬤!那個「gpt-oss:120b」的下拉式選單妳給它按下去蛤,就會出現好多好多文字,那個就是不同的模型可以選啦。那個有一個像「雲一樣」的 icon 就是可以連線到 ollama 去用他們的電腦裡的模型啦,啊有一個「向下指」的箭頭,就是把這個模型下載到妳的頂級 MacBook Pro 16 M5 裡來用。
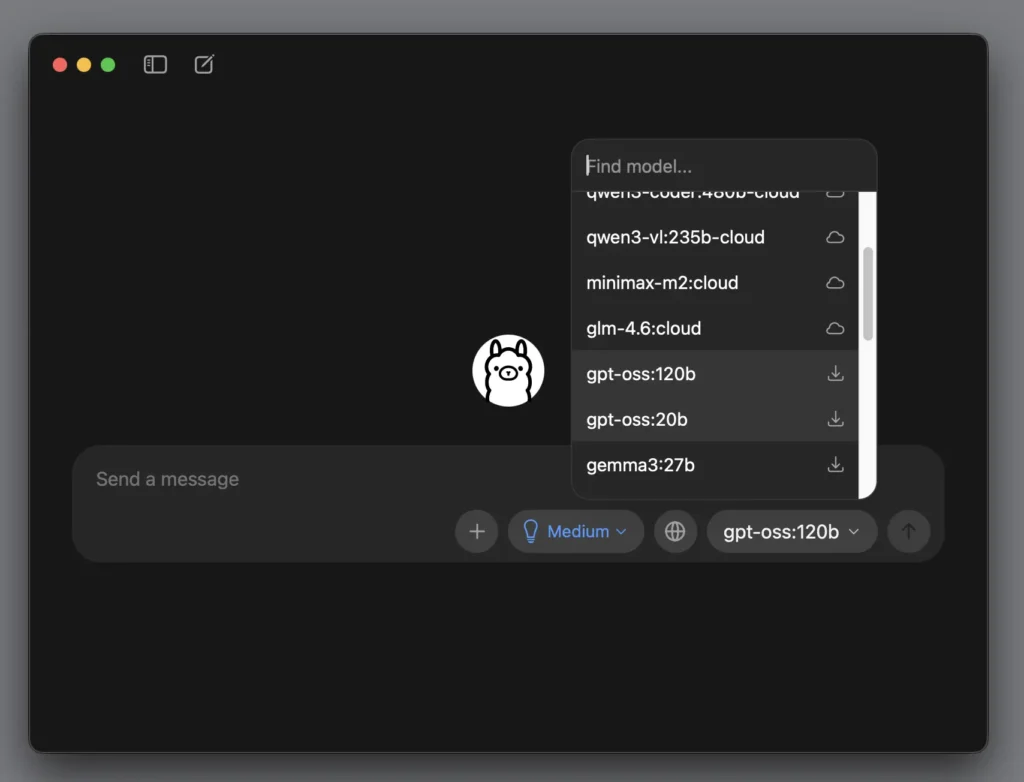
選擇 Ollama 裡的雲端模型教學
第 1 步驟:登入 Ollama 雲端模型
阿嬤,這個有一個像「雲一樣」的 icon 如果選擇了,妳要需要先辦個會員才能請它幫忙啦,但可以用免錢的,我們點一下畫面右邊這個「Sign In」按鈕。
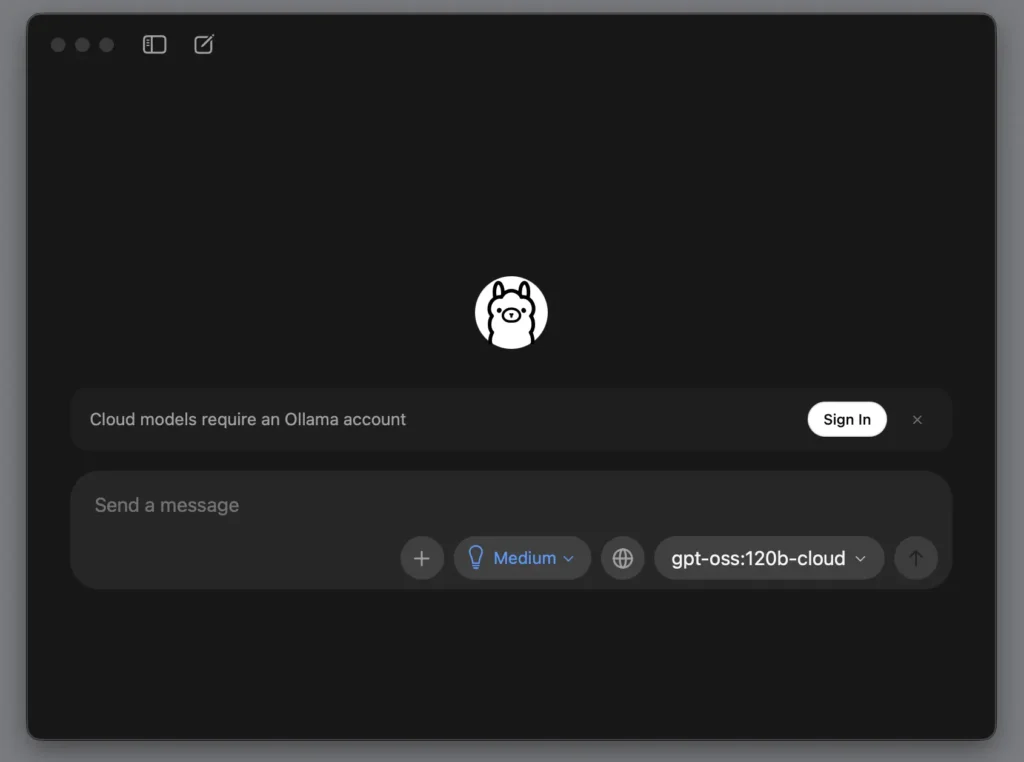
第 2 步驟:登入 ollama
點下去之後,瀏覽器就會看到這個頁面,這裡就像辦會員卡,用妳平常在用的 Google 帳號直接點進去最方便,不用另外記新帳號。
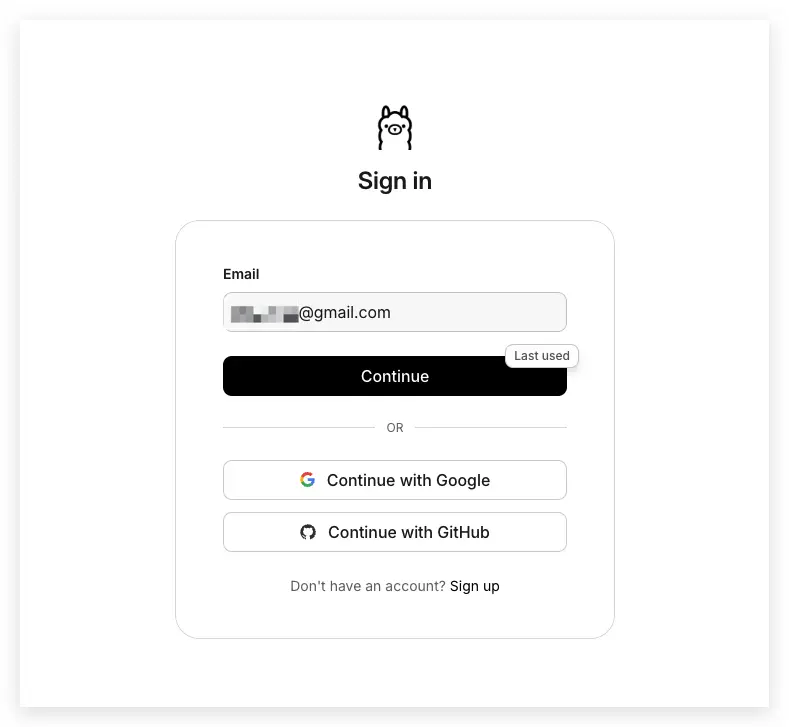
第 3 步驟:連結電腦和 ollama
登入之後,就會看到這個畫面時,點一下中間那個黑色的按鈕,讓妳這台電腦跟會員卡連在一起。
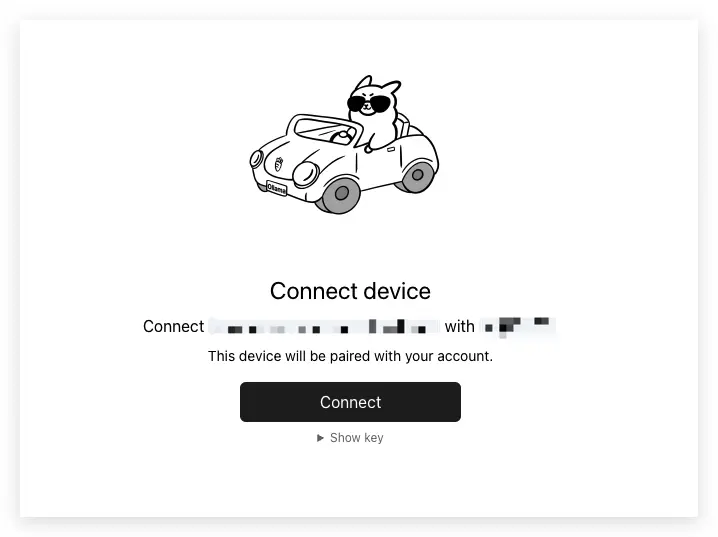
第 4 步驟:連結 ollama 成功
看到這個漂亮的綠色勾勾就是大功告成了,我們可以把這個瀏覽器視窗關掉,回去剛剛的 ollama 了。
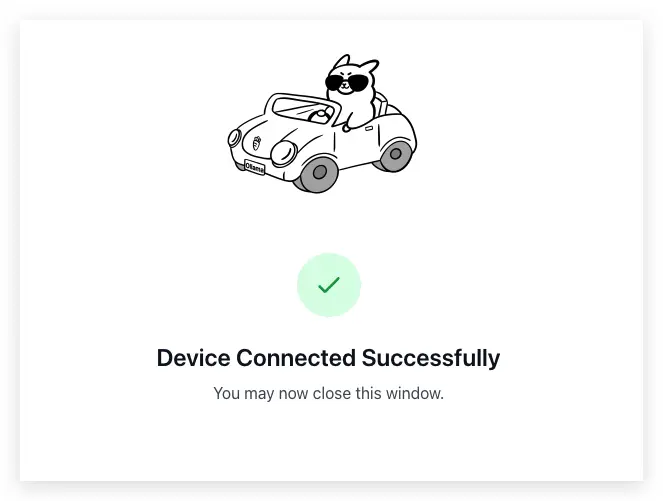
第 5 步驟:返回 ollama
回到聊天室,妳會發現右下角的名稱已經變成雲端的神隊友了,它現在正等著妳說話囉!
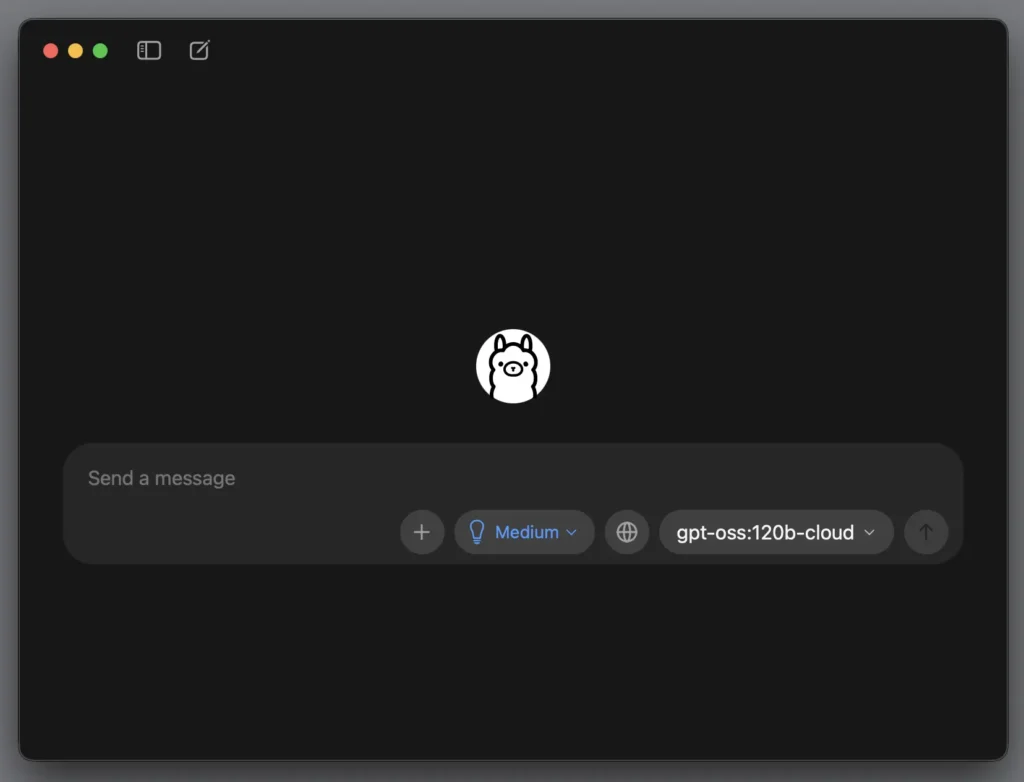
第 6 步驟:向 ollama 提問
隨便考它一個題目,打完字後點一下右邊那個往上的小箭頭,把問題傳出去。
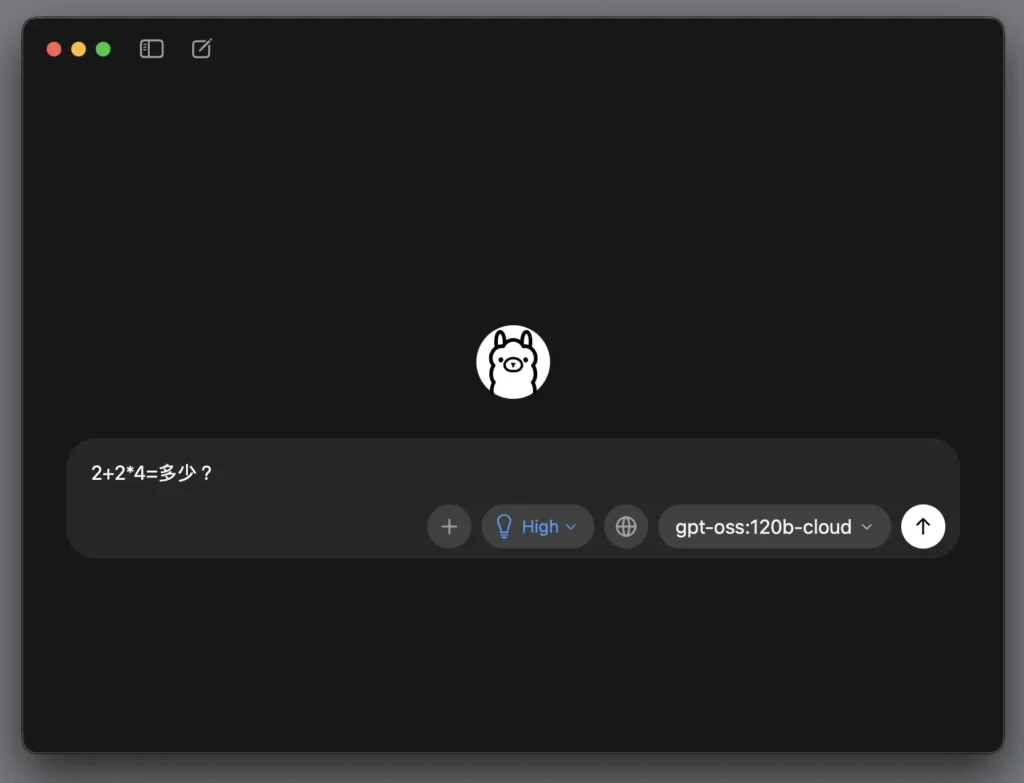
第 7 步驟:向 ollama 提問
AI 就會會老實告訴妳它想了幾秒鐘,然後把算得清清楚楚的答案寫給妳看,是不是非常厲害?比妳問孫子/孫女今天期中考考的好不好回答速度還快。
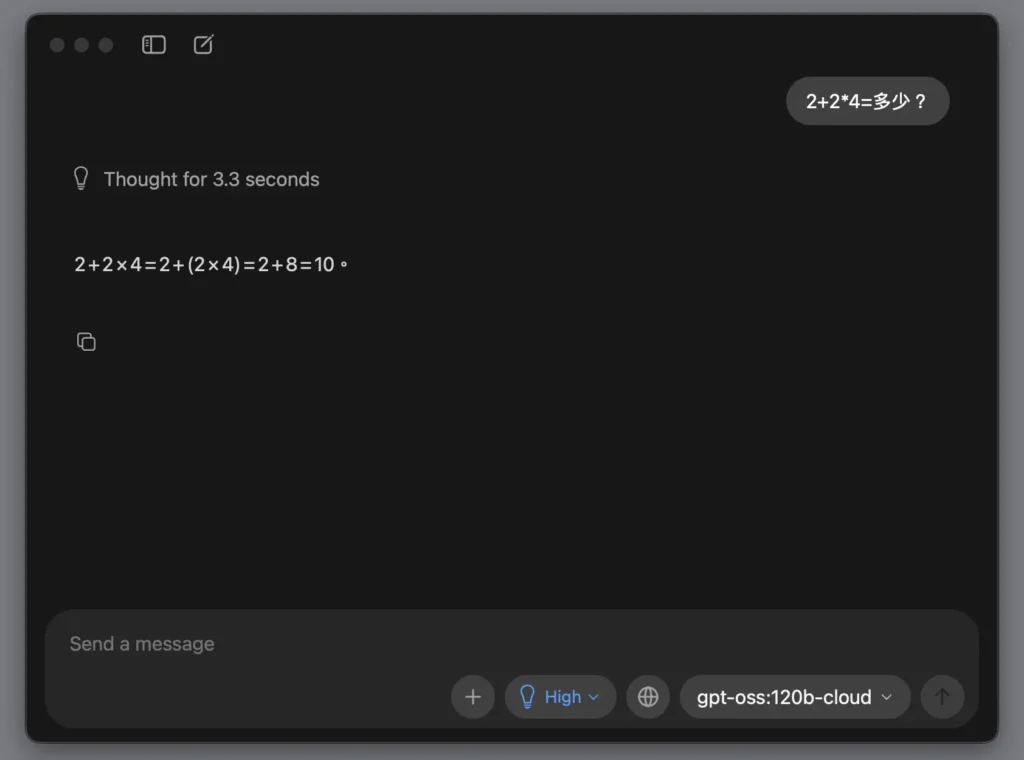
選擇 Ollama 裡的本地模型教學
第 1 步驟:選擇模型
阿嬤,點開右下角的選單,找一個名字旁邊有往下箭頭的模型,這就是可以迎回妳家電腦裡住的模型。
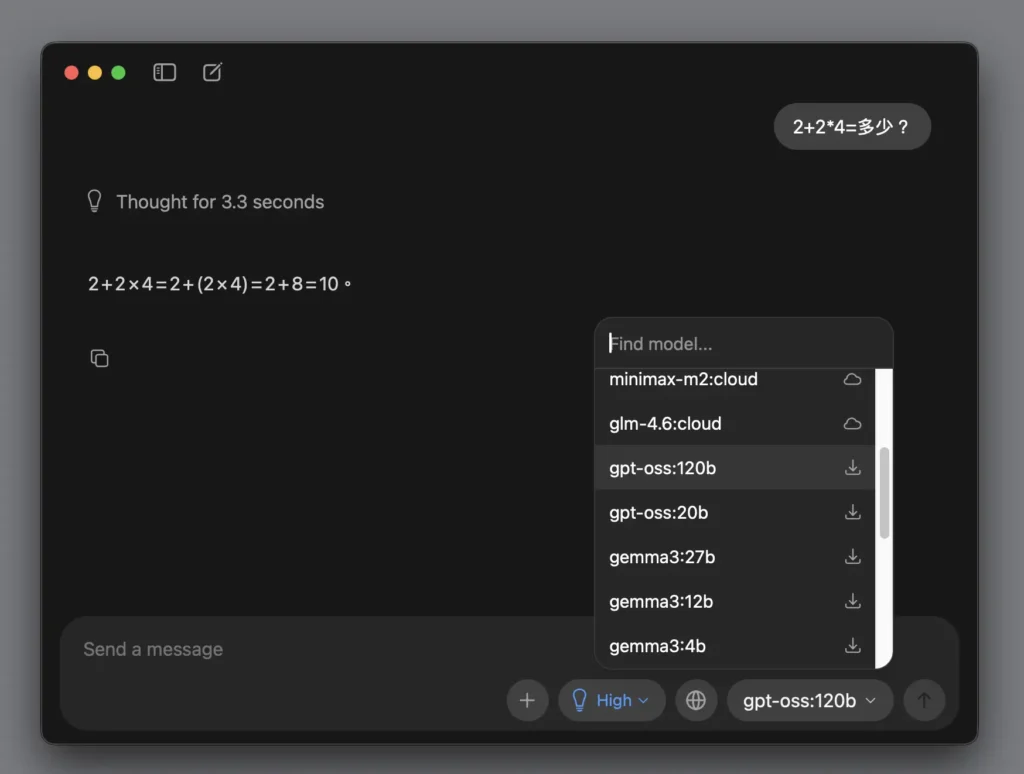
第 2 步驟:先打個招呼
選好新的模型後,我們在下面打個妳好,先跟它打聲招呼。
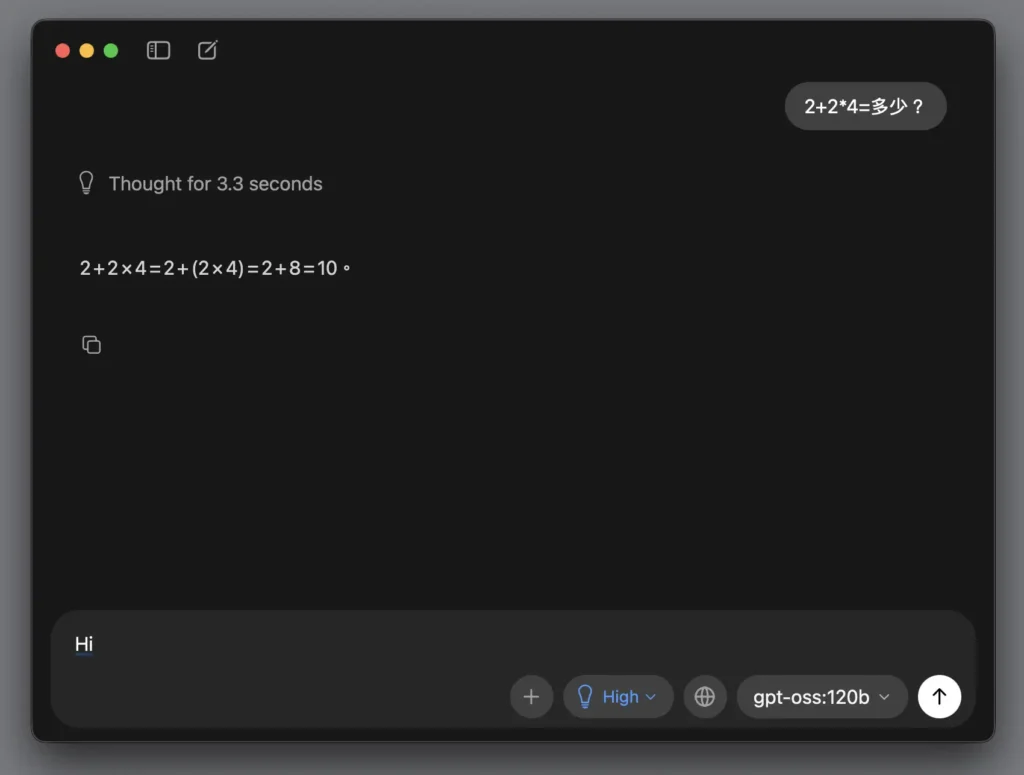
第 3 步驟:開始下載模型
因為這個模型要搬進妳的電腦,我們要給它一點時間搬行李,等這條長長的進度條跑完。
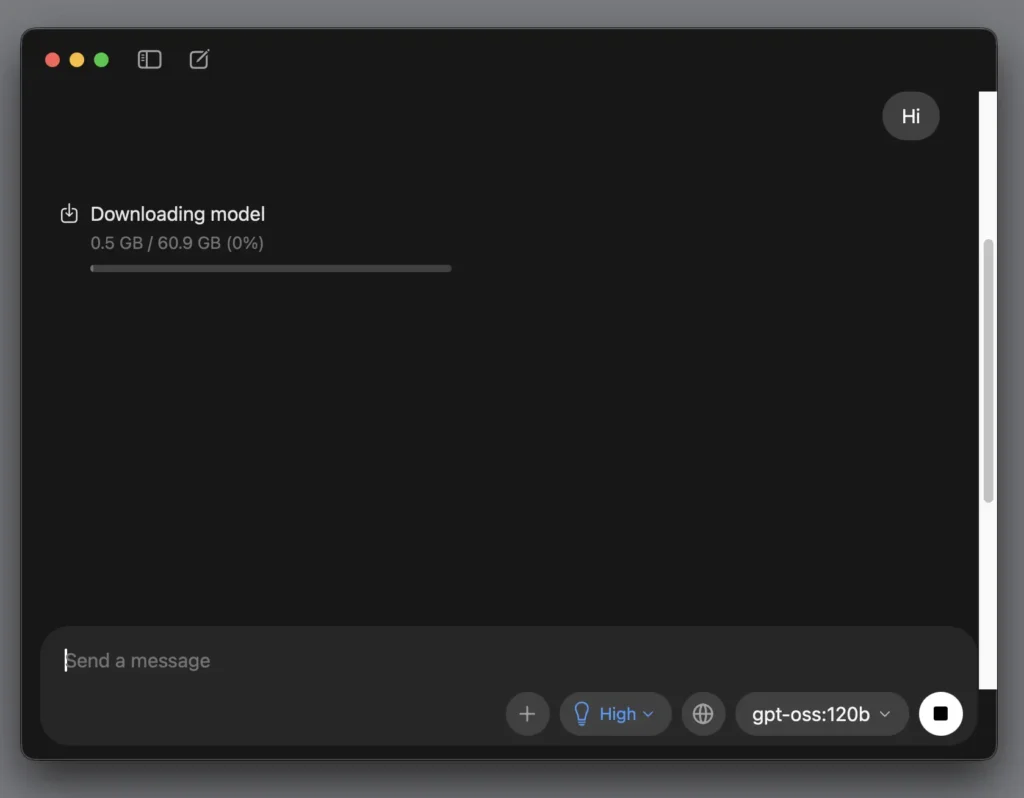
第 4 步驟:模型下載好後,會先跟你打招呼
它搬好家就會開口說話了,會很有禮貌地問妳有沒有什麼要幫忙的地方。
第 5 步驟:對本地模型提問
現在我們可以正式考考它了,輸入一個數學題看看它算得正不正確,我們就用問雲端模型一樣「2+2*4」問題,來問問本地模型。
第 6 步驟:模型會「跑很久」,很正常
如果妳覺得電腦跑得有點慢,那是因為本地模型正在用腦袋幫妳算,這時候讓它專心工作就好,這個時候就會覺得孫子/孫女買的頂規 MacBook Pro 16 M5 不夠快了,要買 NVIDIA DGX Spark 才對。
最後給阿嬤們一個小撇步:選模型時,名字後面的數字越小,跑起來通常越快。不過它能不能答對,就要看妳的問題有多深。這就像請人做工,越厲害的人通常需要電腦花越多力氣去跑。總之,一分錢一分貨,想要 AI 變天才,妳的電腦也要夠強才行,別老想著不花力氣就能請到最好的幫手喔。
Ollama 其他功能教學
以下幾點,主要是在教大家如何管理已經下載到電腦裡的模型,包含查看清單與刪除不需要的模型。
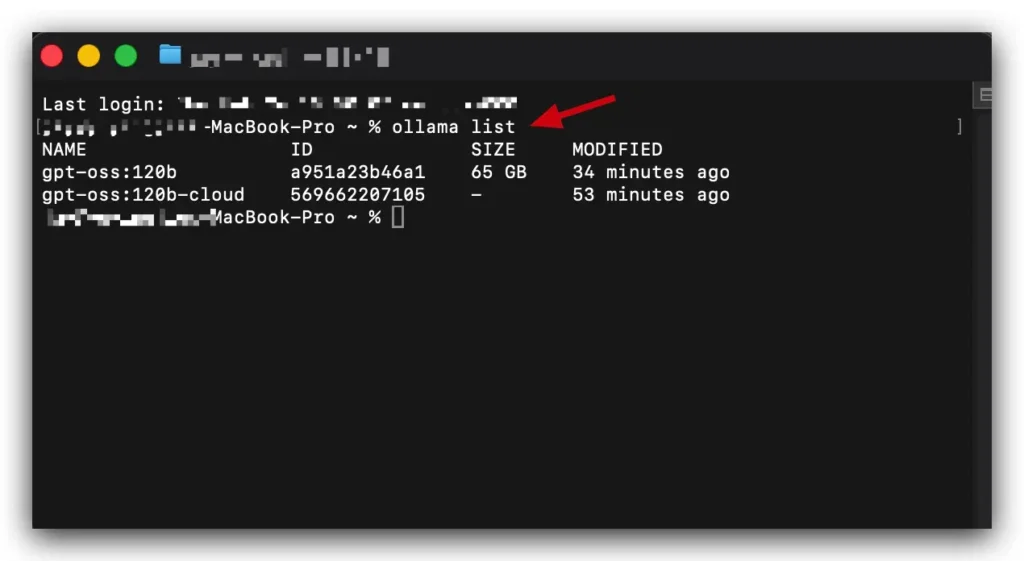
模型有多少個在你電腦裡?
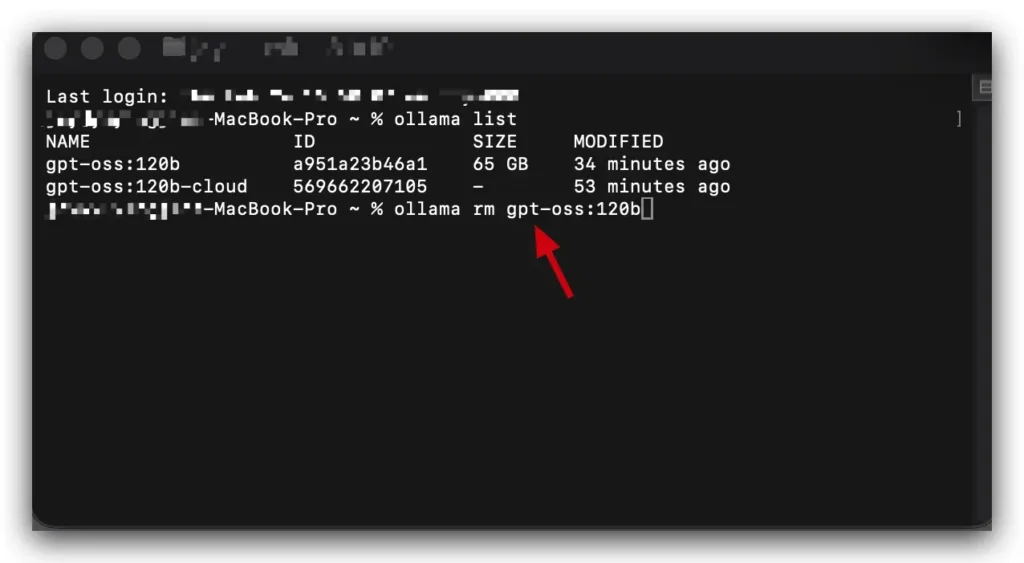
想知道電腦裡到底有多少個模型嗎?只要在 Terminal 視窗輸入 ollama list,系統就會把所有模型排排站列出來,連它們佔用了多少空間都寫得清清楚楚。
刪除本地模型
如果發現某個模型太佔空間,或者想換一個更聰明的,可以在 Terminal 視窗輸入 ollama rm 指令把特定的模型刪掉。
刪除 Ollama 安裝檔
在 macOS 系統上看到這隻可愛的小羊駝圖示,就是我們剛剛用來安裝的 Ollama 程式,可以對著它按右鍵選擇「退出」就好。

常見問題
我真的很在意資料隱私,用本地 LLM 就不會被外洩嗎?
我懂你的擔心。很多人對雲端服務都有點陰影,特別是牽涉到敏感資料的時候。用本地 LLM 就是為了這個目的設計的。所有的處理都只在你的電腦裡發生,不經過網路,也不會上傳到任何伺服器上。你可以把它想成一個沒有對外網路的保險櫃,鑰匙只在你手上。
它跟 ChatGPT 有什麼不同?會不會比較笨?
這是很多人會問的問題。ChatGPT 是跑在 OpenAI 的雲端伺服器上,而本地 LLM 是你自己下載模型回來、在本機啟動。效果上,如果選對模型,其實差距沒有大家想像中大。日常用來對話、寫文案、翻譯,很多本地模型也做得很好。更重要的是,你的資料會完全留在自己的電腦裡。
Ollama 跟 Open Web UI 是什麼關係?為什麼要兩個?
Ollama 就像是 AI 模型的啟動器,負責載入與運行模型。Open Web UI 則是操作介面,讓你不用打指令,也能用瀏覽器和模型互動。簡單講,一個是背後的引擎,一個是前台的操作台。兩個搭配使用,整體體驗會輕鬆很多。
我電腦只有 8GB RAM,還可以玩嗎?
可以,只是需要選擇比較輕量的模型。像 mistral:instruct-q4 或 gemma:2b-it-q4_K_M 都是相對輕巧又好用的選擇。很多人會以為要玩本地模型一定要高階設備,其實不是,從小的開始也能做到很多事。
模型檔案好大,下載完是不是很佔空間?可以刪嗎?
可以。模型通常會存在 ~/.ollama 這個資料夾裡。如果你不再使用某個模型,可以直接把它刪掉。以後需要再用的時候重新下載就行。這是彈性的,不需要一直保留在電腦中。
我怎麼知道哪個模型適合我?要怎麼挑?
我通常會看三件事:模型大小(幾 b)、模型用途(像是 instruct、chat、code),還有量化版本(q4 是比較穩的選擇)。如果你剛開始玩,建議從 mistral、llama2、gemma 系列開始,這幾個相對穩定又不難用。
我不太會下指令,可以只用圖形介面嗎?
當然可以。Open Web UI 就是設計給不熟指令的人使用的。整個介面用滑鼠操作即可,介面直覺,進去後就像用聊天機器人一樣自然。
我想拿來寫程式或當 AI 助手用,有推薦的模型嗎?
如果是寫文案、生成內容,可以考慮 mistral-instruct、zephyr、openhermes。要寫程式的話,像 deepseek-coder、code-llama、Qwen2-coder 都是不錯的選擇。如果想練英文,llama2:chat 或 gemma 系列也很適合。
這些工具能不能應用在我自己的產品或專案裡?
可以,而且空間很大。你可以拿來做客服機器人、部落格寫作助手、簡單的對話式小工具,甚至結合自己手上的資料做 RAG(Retrieval-Augmented Generation)系統。只要你願意學,就會發現這些模型有很多可能性。
我很怕裝錯,有沒有簡單的安裝流程?
這篇文章就是為了幫你減少試錯而寫的。我已經把每個步驟拆得很清楚,包含可能出錯的地方、怎麼確認是否成功。只要照著做,基本上可以很順利地完成設定。如果有卡關的地方,你也可以問 ChatGPT,它會盡量幫你找出問題。
要深入了解 AI 產品經理的基本職責和角色,請參考我的詳細指南:AI 產品經理,我的學習方法