
Gemini 是 Google 近年來,AI(人工智慧)的重中之中,而在 AI 這場比賽當中,產生了許多強大的「大模型」。其中,Google 與 OpenAI 推出的 AI 模型是大家關注的焦點。
在 Google 方面,他們推出了 Gemini 系列模型(1.0、1.5、2.0、2.5 等),而 OpenAI 則有以 GPT 為基礎的 ChatGPT,這兩大陣營可以說是 AI 領域的兩條巨龍,它們之間的較量宛如一場重量級對決。
本文將從技術演進與比較的角度出發,用簡單明瞭的說法,介紹 Gemini 與 GPT 背後的核心原理、不同特點,以及各自的優勢,讓沒有技術背景的阿嬤也能理解這場 AI 大戰的重要性與精采之處。
Gemini 的發展歷程
在你開始深入了解 Gemini 之前,這邊有個小故事要先告訴你。你現在使用的這個 Google AI 聊天機器人,雖然現在叫做 Gemini,但在 2023 年 3 月剛推出的時候,它其實有一個很詩意的名字,叫做 Bard(「吟遊詩人」的意思)。
Bard 一開始是基於 Google 另一套比較早期的模型 LaMDA 所開發出來的,主要是為了應對當時 ChatGPT 突然爆紅的局面。
到了 2024 年 2 月,Google 推出了更強大、更統一的 Gemini 模型系列(就是我們下面要講的 1.0、1.5 等)。為了讓產品線看起來更清楚、更一致,Google 決定讓 Bard 「升級更名」,直接變成 Gemini。
簡單來說,Bard 是這位 AI 助手的第一個名字,而 Gemini 則是它最新的、代表最強大技術狀態的名字。這就像是這位 AI 助手從一位「吟遊詩人」進化成了一位「全能學霸」。
Google 在 2023 年底推出了第一代 Gemini(Gemini 1.0),並逐步發展到後來的 1.5、2.0 甚至 2.5 版本,每一代都有新功能與進展。我們先按時間順序看一下主要里程碑:
Gemini 1.0 (2023年底):Google 在 2023 年 12 月宣布推出 Gemini 1.0,是當時「最強大的 AI 模型」之一。Gemini 1.0 實際上包含三個版本:
- Gemini Ultra:最大、最強大的版本,用於處理超級複雜的問題(如解難數學、做研究)。
- Gemini Pro:中型版本,擅長各種常見任務(像是一位萬能的全科老師)。
- Gemini Nano:最小、最省資源的版本,設計用在手機或其他裝置上(就像把 AI 小型化,用在手機等設備)。
這三種不同大小的版本好比運動隊裡的三種選手:超級明星(Ultra)、全能選手(Pro)、快速選手(Nano),滿足不同情境需求。Gemini 1.0 在語言理解、多模態(同時處理文字、圖像、音訊等)方面表現出色,經過多項測試後,Gemini Ultra 在 32 個常用的語言理解基準測試中有 30 項達到或超越當時的最高水準。其中,在 MMLU(多任務語言理解)測試中,它拿到 90% 的分數,成為第一個超越人類專家水準的模型。簡單說,Gemini Ultra 就像是一名學霸,在全校聯考中考出了超過老師們的平均水準,證明了強大的「腦袋」和學習能力。
Gemini 1.5 (2024年2月):接著,Google 在 2024 年初推出 Gemini 的升級版 1.5。 新版本最大的改進,就是採用了「專家混合(Mixture-of-Experts,MoE)架構」,以及大幅增加的上下文理解能力。
這裡稍微解釋一下:MoE 架構好比組建了一個由多位「專家」共同工作的團隊,每個「專家」都專精不同領域,就像奧林匹克代表團裡,有不同項目的教練團隊,當遇到問題時,模型可以「叫」出最合適的專家來參與運算,這樣在訓練和執行時就能更快、更有效率,我這篇文章DeepSeek 的 MoE 架構:低算力下的大語言模型高效訓練技術有詳細的說明。
具體來說,Gemini 1.5 Pro 這個版本在運算上達到與之前最大型的 Gemini Ultra 相當的品質,但使用更少的運算資源。此外,Gemini 1.5 Pro 的標準上下文窗口大小為 128K 字元(和 GPT-4 Turbo 相同),但它還實驗性地提供了長達 100 萬字元的閱讀能力,這是迄今為止最大的大模型上下文窗口。
翻成白話文說,GPT-4 Turbo 一次最多可以閱讀約 300 頁的文字,而 Gemini 1.5 在測試中可以一次讀進大約一千多頁(一百萬字)以上的文字內容。
換句話說,Gemini 相當於是一位可以同時掌握整整一整個圖書館資訊的學霸,而 GPT-4 Turbo 則像能快速閱讀一本小說的速讀王。
Gemini 2.0 (2024年12月):在 2024 年底,Google 推出更先進的 Gemini 2.0 系列,並且首次強調了「agent」(智能代理)的概念。2.0 版本引入了 2.0 Flash 模型,據稱它在速度和效能上大幅提升:2.0 Flash 在核心測試上超越了1.5 Pro,而且推理速度快了兩倍。它也繼承了之前多模態的能力:不僅可以輸入文字、圖片、影片和音訊,還可以「輸出」圖片和語音,例如直接生成圖像、用多種語言說話。
更厲害的是,2.0 Flash 原生支援「工具呼叫」,意思是它可以直接連到 Google 搜尋、執行程式碼、或呼叫用戶自訂的函式,來幫助解答問題。
想像一下,你用手機上的 Gemini 2.0 聊天,不只可以打字問問題,還可以傳圖片給它,它不但能讀懂圖中的內容,還能把回答用人聲朗讀出來,甚至上網查資料給你看。Google 還在 Gemini 2.0 中啟動了各種實驗計畫(比如 Project Astra、Mariner、Jules),探索 AI 代理如何在真實場景中幫助人們做事,這顯示出 Gemini 2.0 不只是被動回答問題,更朝向「主動幫助使用者完成任務」發展。
Gemini 2.5 (2025年3月):最新一代 Gemini 2.5 進一步強化了「思考」與推理能力。官方表示,Gemini 2.5 是為了解決愈來愈複雜的問題而設計,被稱為「思考模型」。截至 2025 年 3 月,首個公開的 2.5 版本(2.5 Pro 實驗版)在常見基準測試中領先其他模型,而且在推理和程式編碼能力上有極強表現。
簡單說,它不僅能回答問題,還特別擅長解決複雜的算術和邏輯問題,甚至寫程式。可以想像,它就像是一位不但懂得背誦教科書,還能像高水準的數學老師或資深程式設計師一樣,透過邏輯推理給出答案。
Gemini 3 (2025年11月):不再只是「出一張嘴」,它長出「手腳」了
原本大家還在猜測 Gemini 3 會不會去打機器人市場,結果 Google 在 2025 年 11 月直接給出了答案:這次進化的重點不是「身體」,而是讓 AI 變成了真正的「代理人(Agent)」。
如果說半年前發布的 Gemini 2.5 是一位「絕頂聰明的顧問」(腦袋很好,會深度思考),那麼現在的 Gemini 3 就是一位「手腳俐落的超級管家」。
為什麼這麼說?讓我們用最白話的方式來看這次的三大進化:
- 從「回答問題」變成「幫你做事」 (Agentic): 以前你問 AI:「怎麼去羅馬玩?」它會給你一長串文字攻略,然後你自己還是要去訂票、查地圖。 現在的 Gemini 3,你可以把它當成真正的助理。你跟它說:「幫我規劃去羅馬的行程,順便把機票比價結果寄給我老婆。」它不只會規劃,還能自己去呼叫地圖、搜尋機票、打開 Email 寫信,幫你把這一連串動作直接做完,不用你當傳聲筒。它從「動口」變成了「動手」。
- 會變魔術的介面 (Generative Interfaces): 這點最神奇。以前 AI 回答你,永遠都是一堆文字或圖片。 現在 Gemini 3 如果覺得文字講不清楚,它會「現場寫一個小程式」給你用。例如你想算房貸,它不會只給你公式,而是直接在對話框裡生成一個「可以按、可以拉動的房貸計算機」;你想看行程,它直接生成一個互動地圖給你點。它能根據你的需求,隨時變出最適合的「畫面」。
- 最有默契的工程師 (Vibe Coding): 對於寫程式的人來說,Gemini 3 被稱為最懂「氛圍」(Vibe)的 AI。意思就是,它不再只是死板地寫代碼,它能看懂你整個專案的風格。就像一個跟你合作多年的老同事,不用你多說,它就知道你喜歡怎麼命名變數、喜歡哪種架構,寫出來的程式碼不僅能跑,還很合你的胃口。
簡單總結一下進化史:
- Gemini 1.5 是讀了很多書的學霸(讀書快、記憶力好)。
- Gemini 2.5 是學會了深度思考的博士(邏輯強、不亂說話)。
- Gemini 3 則是終於走出實驗室,變成了一位能幫你跑腿、做圖表、搞定雜事的全能執行長(執行力強)。
這樣的演進過程顯示,Google 在不斷強化 Gemini 的能力:從最初的多模態大模型,到後來加入專家混合架構和超大閱讀能力,再到支援多輸入多輸出的互動代理,最後強調推理與編碼。每一步都像是在建造更強大的大腦,讓 Gemini 在理解資訊和幫助人做事上更全面、更強大。
Gemini 3.1 Pro 正式發佈了
官方的說法很明確:3.1 Pro 是把 Gemini 3 Deep Think 的核心推理能力,做成更適合實際任務落地的版本。它的定位不是「聊天更像人」,而是「能處理更複雜的工作鏈路」,包含資料、介面、規則、程式碼這種需要同時顧好幾條線的任務。
為什麼說它是新的基準
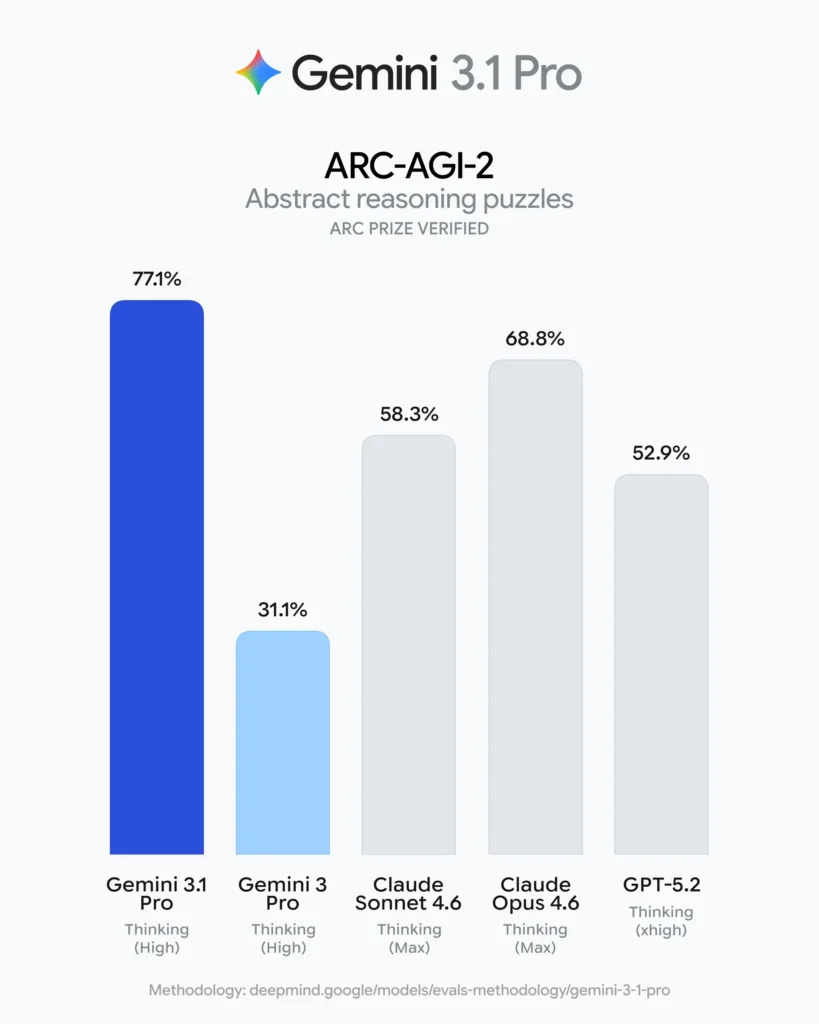
這次 3.1 Pro 最醒目的數字是 ARC-AGI-2 拿到 77.1%。
ARC-AGI-2 這類測試,重點在「解全新邏輯模式」:你沒看過的規則,模型能不能自己推理出來。官方也直接拿上一代 3 Pro 做對照,說 3.1 Pro 的表現是兩倍以上的躍進,換句話說,3.1 Pro 被包裝成一個在核心推理上明顯升級的版本,而且是用一個非常「吃推理」的基準測試來當主打。
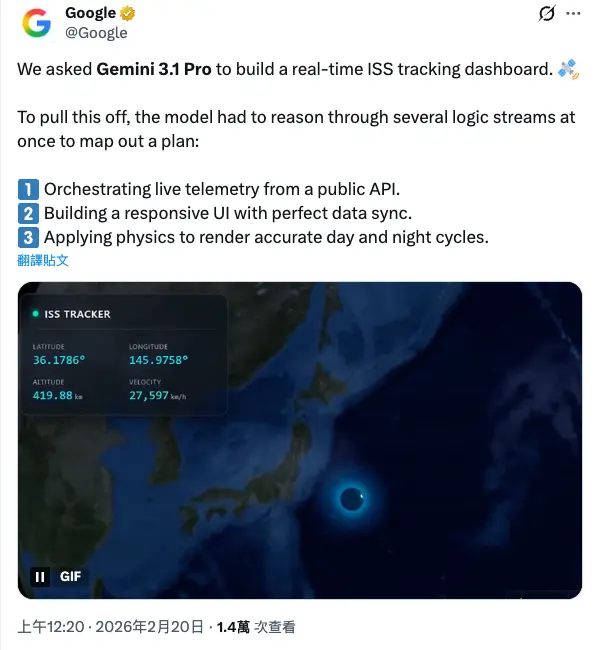
官方示範想傳達的訊息其實只有一件事
他們用一個任務當例子:模型要同時做到三件事
- 協調公開 API 的即時資料
- 做出RWD UI,資料同步要精準
- 套用物理規則,呈現正確的日夜循環
這段示範的重點不在於「API、UI、物理」本身,而是它在強調 3.1 Pro 的能力是「多條邏輯流並行推理,再收斂成一個可執行方案」。
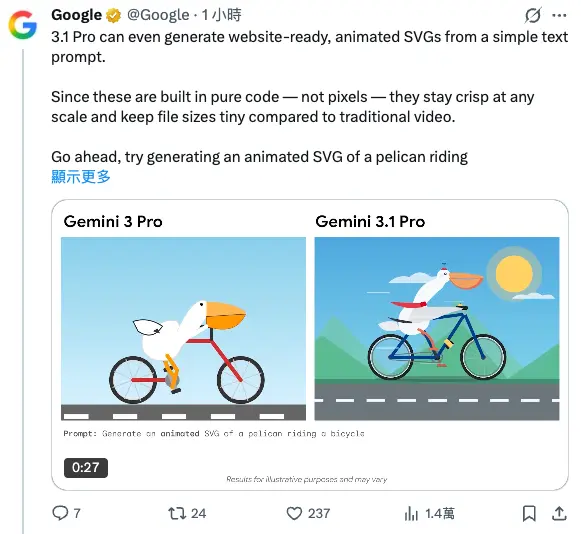
它不只會寫 code,還會產出可直接上線的素材
另一個很具體的亮點是:3.1 Pro 可以用文字提示,生成網站可用的動畫 SVG。
SVG 是純程式碼,不是像素影片,所以放大依然清晰,而且檔案通常比傳統影片小,官方甚至直接給了一個挑戰題:用一句話生成「騎腳踏車的鵜鶘」動畫 SVG,這種示範要傳達的其實是:它不只回答你,還能把成果變成可直接放進網頁的交付物。
創意專案也被納入它的主打能力
官方也展示了 3.1 Pro 在「風格推理」上的表現:例如基於《咆哮山莊》做作品集網站。
重點不只是摘要小說,而是把小說的氛圍、角色張力轉成 UI 設計,並產出網站可用程式碼。這在官方敘事裡代表 3.1 Pro 不只做邏輯題與工程題,也想把「理解抽象風格」納入其推理能力範圍。
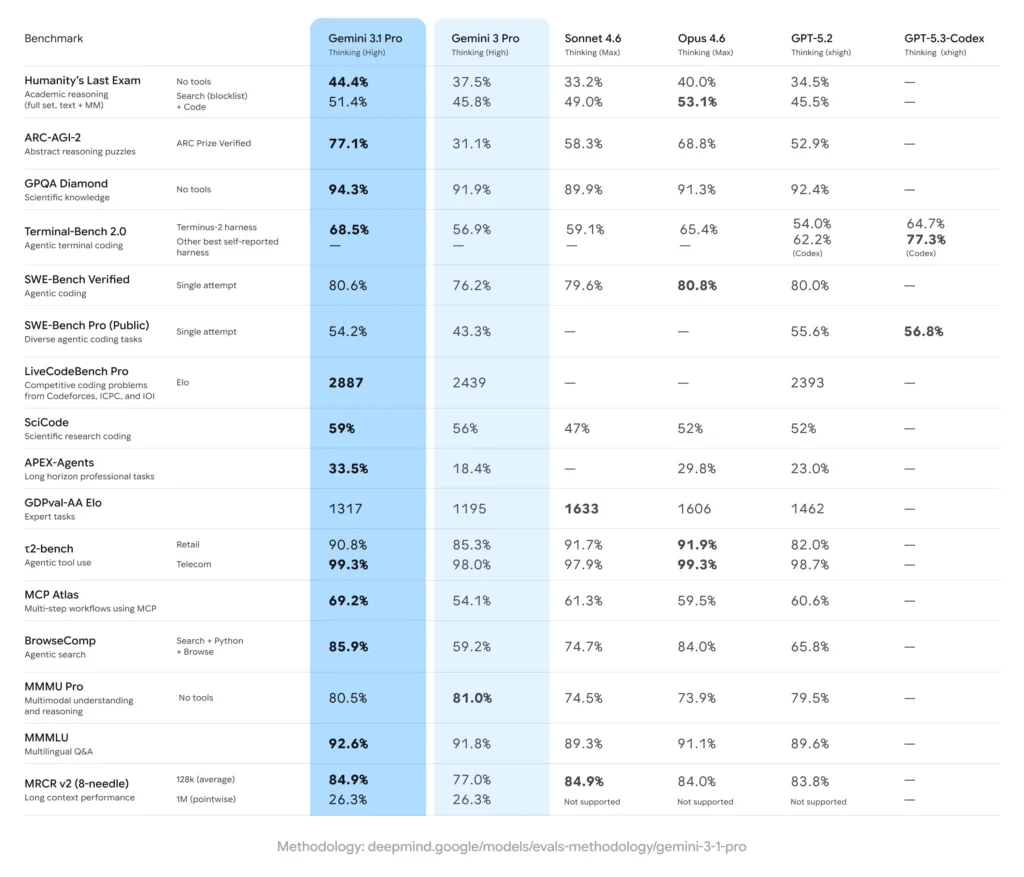
更多 benchmark:你應該怎麼看
官方列了很多分數,但可以用一句話理解:3.1 Pro 的定位是一個「複雜任務基準模型」,所以評估項目橫跨推理、科學知識、代理式程式開發、工具使用、多模態理解等面向。
你不需要一個個背數字,重點是官方用這些測試來證明:3.1 Pro 的提升不是單點,而是想涵蓋「需要多步驟規劃與執行」的整體能力。
Gemini 3.1 Pro 上線時間與資訊
Gemini 3.1 Pro 從今天 2026 年 2 月 20 日開始陸續推出,官方公告與細節在這裡:
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro
Gemini 的核心技術
為了讓阿嬤也能理解,我們來簡單解釋 Gemini 和 GPT 背後常見的技術名詞和概念:
Transformer 架構
Transformer 是現代 AI 語言模型的基礎架構。你可以把它想像成一套特別設計的「理解語言的大腦」。它的特色是「注意力機制」(self-attention),就像閱讀文章時,每個單字都能「注意到」其它單字的重要性。
換句話說,它不只是直線讀字,而是同時考慮整句每個詞之間的「關聯」,找出最關鍵的訊息。就好像在看一段長長的文章時,你的大腦不會只專注單詞順序,而是會注意到哪些關鍵詞是重點。
這種 Transformer 架構讓 AI 模型可以迅速處理大量文字,理解複雜的關係,以及人與人之間的連結。
OpenAI 的 GPT 系列和 Google 的 Gemini 都是基於 Transformer 架構來建造的,只是各自做了不同的改良。因為 Transformer 架構很厲害,能讓模型「同時讀懂整段話」,才有辦法像 ChatGPT 一樣回答問題、寫文章;也讓 Gemini 能處理語言、圖像等多種資料。
Token 與上下文窗口
AI 模型處理文字時,不會以一個個完整句子或段落去計算,而是會把文字拆成 Token,就像把句子切成許多拼圖塊。每個 Token 可能是一個字、一個英文單字,或是一個子詞(像把「電腦」拆成「電」和「腦」)。
模型「閱讀」時會一一把這些詞元進輸入的大腦中,而上下文窗口(context window)就是這個大腦一次能注意多少 Token 的數量,它決定了模型能「同時看到」多少文字。
舉例來說,GPT-4 Turbo 的上下文窗口是 128K 個 Token,相當於一次可以讀約 300 頁的文本,而 Gemini 1.5 在實驗中能一次讀進 1,000,000 個 Token,也就是一次讀進將近一千頁以上的內容。
打個比方,GPT-4 Turbo 就像一位讀者可以一下子拿起三百頁書來閱讀,而 Gemini 則像能把圖書館幾千頁的書一次拿出來看。上下文窗口越大,模型在回答時就能參考更多前文資訊,就像在解決問題時能看更多題目上下文。
對你來說,可以把 GPT-4 Turbo 想成能「同時讀三百頁書」的優秀學生,把 Gemini 想成能「一次翻開十本書」的大學者,Gemini 因此在需要理解超長文本或大篇幅資訊的任務上,具有明顯優勢。
專家混合(Mixture of Experts,MoE)架構
這是 Gemini 1.5 引入的重要技術。 我們可以把它想像成一支專家團隊。假如你問一堆問題,這支團隊裡面有很多教練或老師:有講數學的、講歷史的、講自然科學的……每個人都是某個領域的專家。
MoE 架構會有一個「分派系統」(Gating network),幫你把問題轉交給最合適的專家來解答,比如看到數學題就找數學老師,看到歷史題就叫歷史老師。
這樣做好處是,每個專家只要負責自己擅長的部分,整體算力就能更省、更準確。據說 Gemini 1.5 Pro 就把請求分配給多個「專家網絡」一起算,讓回應更快、品質更高。換句話說,引入 MoE 就像運動隊有多位教練分工指導,可以因材施教,特長突出,加速了訓練和預測的速度與效能。
多模態(Multimodal)能力
顧名思義,多模態就是能處理多種「模式」(類別)的資料,不只是文字還包括圖像、音檔、影片等。Gemini 從一開始就以多模態聞名。根據 Google 的說法,Gemini 不是只讀文字,它還同時在訓練中吃了圖像、音檔、影片字幕、程式碼等各種資料。
這就像一個學生不僅看書,還看圖片、聽講解、看影片、寫程式……透過不同管道學習。和過去常見先單獨訓練文字模型,再另外拼貼圖像模型的作法不同,Gemini 是從頭就同時學各種資料,所以能更自然地理解文字與圖片的關係。
這種原生多模態的設計讓 Gemini 在理解圖文混合的信息時非常強大,比如它可以直接「看看」圖片內容並回答問題,而無須額外的光學字符辨識工具。簡單比喻,Gemini 就像是一個全能型的學生,不但能閱讀文章,還能「看」照片、聽聲音,並且把它們串聯起來理解;而 GPT-4 原本是專門讀文字的,後來才陸續加上看圖片的功能(例如 GPT-4 Turbo 也可以接受圖像輸入),但 Gemini 在多模態一體化訓練上更早、更徹底。
運算硬體:TPU 與其他加速器
大模型需要超大算力才能訓練出來。Google 為 Gemini 提供了自家設計的專用晶片,叫做 TPU(Tensor Processing Unit,張量處理器)。可以把 TPU 想像成專門用來訓練 AI 的超級賽車引擎,比一般的 CPU 或 GPU 還要快很多,可以參考我這篇《Google TPU 是什麼?專為 AI 設計的專用晶片》文章有詳細說明。
根據報導,Gemini 從 1.0 開始就是在 Google 最先進的 TPU 上訓練。事實上,Gemini 在公布時就表示整個模型都是用 TPU 訓練和執行的。類比而言,如果你要比賽賽車,用一般汽車(CPU/GPU)可能跑不快,但用 Formula 1 賽車(TPU)就能飛快到達。OpenAI 的 GPT-4 主要訓練在 GPU(圖形處理器)上,而 Google 的 Gemini 用自家 TPU,這也形成了兩家不同的「AI 賽車場」。
這些技術名詞當然看起來很專業,但簡單說:Transformer 和 MoE 是大模型的大腦結構;詞元和上下文窗口決定它一次能看多少文字;多模態讓它像人一樣能聽圖文並茂;TPU 是讓它「動起來」的超強硬體。了解了這些基礎,就能更清楚下面比較 Gemini 和 GPT-4/Turbo 時它們的優劣。
Gemini 與 GPT 比較
接下來,我們把前面講的兩邊放在一起比較,看看 Gemini 和 GPT 各有哪些特色,誰在什麼方面更強:
模型訓練資料
Gemini 與 GPT 都是用海量資料訓練出來的大模型,不過各自來源與設計上有差異。Gemini 的一大特色是「多模態訓練」,它從一開始就同時吞了文字、圖片、影片、音檔甚至程式碼,這讓它對各種資訊都有過濾的理解能力。
例如,Google 報導說 Gemini 不只是看網頁文字,它還看了 YouTube 影片的逐字稿(當然經過法律篩檢去掉版權問題),所以學到了很多語境和對話技巧。GPT-4 則主要是用文字資料訓練(雖然後來也有開放 ChatGPT 讀圖功能,但本質上GPT-4原本是文字模型)。
在知識學習截止時間上,OpenAI 提到 GPT-4 Turbo 的知識更新到 2023 年 4 月。Google 沒明說 Gemini 的資料截止到什麼時候,但至少 Gemini 1.5 (2024年2月)應該比 GPT-4 Turbo 的截止日期要近一些,也就是含蓋較新的資訊。總之,Gemini 倾向於一開始就吸收多元資料,而 GPT-4 Turbo 則以龐大文字知識為主,且兩者都經過不同方式的篩選與學習。
閱讀理解長度
如前所述,Gemini 能讀進的文字內容遠大於 GPT-4 Turbo。這對我們來說這意味著:假設要把一長篇文章的內容都丟給模型理解,GPT-4 Turbo 大概能一次性讀入一份幾百頁的文件,而 Gemini 甚至可以處理上千頁資料。
這對需要分析長文檔、報告或開一整本書的情境很有用。想像要寫一份研究報告,Gemini 可以把整本參考書都裝進它的「腦袋」中;GPT-4 Turbo 在這方面就比較吃力,需要分段查詢或使用輔助工具。
多模態處理
Gemini 天生多模態,在理解圖片、影片結合文字的任務上通常有優勢。舉例來說,如果你給它一段故事,還附上一張相關圖片,Gemini 會將圖文結合起來理解。GPT-4 Turbo 也能處理圖片,但畢竟是後來添加的功能。這並不是說 GPT-4 Turbo 在視覺任務上就很弱,而是說 Gemini 的設計從頭到尾就考慮了圖文並存,理論上對多模態的整合更「原生」。
實際測試顯示,Gemini 在各種圖文與視覺理解基準上跑分超越了之前很多模型,並且很多情況比需要額外 OCR (文字辨識) 才能看圖的模型表現更好。因此,對於圖像理解或是圖文結合的應用(例如,對著圖說故事、解讀化學結構式等),Gemini 可能更勝一籌。
性能與推理能力
在文字和數據推理方面,Gemini 也表現優異。之前提過的 MMLU 基準,Gemini Ultra 首度超越了人類專家;而 GPT-4 Turbo 雖然具備強大的推理和常識知識,但是否超越 Gemini 則取決於任務類型。根據一些非官方的測試與分析,Gemini 1.5 Pro 在一些推理和常識題上略優於 GPT-4 Turbo,但 GPT-4 Turbo 在其他任務(尤其是成本效率和對指令的嚴格遵守)上還是很有優勢。
2025 年 3 月發布的 Gemini 2.5 更是在領先基準上勝出,多數公認它在解題和程式編寫上的推理能力非常強。簡言之,最新的 Gemini 型號號稱推理力超群;而 GPT-4 Turbo 也不遑多讓,在常規語言理解和格式化輸出方面經驗老道。哪一邊更強,可能要看具體問題和測試,兩者都能完成大部分高難度的語言任務。
速度與成本
由於 Gemini 1.5 採用 MoE 架構,Google 宣稱它可以在訓練和執行時更高效。換句話說,同樣能力下,Gemini 1.5 可能用更少算力就達到效果。另一方面,OpenAI 的 GPT-4 Turbo 主打「便宜又快」,每處理 1K 個 Token 的成本只有原本 GPT-4 的一小部分。對普通使用者來說,這代表 GPT-4 Turbo 可以在維持良好表現的同時,減少使用費用。
實際上,OpenAI 明確指出 GPT-4 Turbo 的輸入成本只有原 GPT-4 的 1/3,輸出成本只有 1/2。兩者在速度上都相當快速:Gemini 2.0 Flash 已經實現了每次回答都能很快回饋,用戶感覺響應延遲很低;GPT-4 Turbo 也是最佳化過的版本,比早期 GPT-4 回應更迅速。換句話說,這就像比較兩輛跑車:Gemini 的跑車引擎(硬體 + MoE 架構)讓它加速更快更省油,GPT-4 Turbo 的跑車則以較低的油耗(成本)著稱,兩邊都有高效率的設計。
生態系統與應用
最後,兩家公司將模型應用到不同服務中。Gemini 已經和 Google 的多個產品結合:像是 Google 搜尋、Chrome 瀏覽器、Google Workspace 內建的智慧助手等,都會用到 Gemini 的能力。OpenAI 則是把 GPT-4 Turbo 推到了 ChatGPT、DALL·E 3(圖像生成)等服務中,也開放 API 給開發者。對普通使用者而言,ChatGPT 使用者幾乎每天都在和 GPT-4 Turbo 互動,Google 服務用戶也很快會體會到 Gemini 的影響。這場 AI 對決的精彩之處,在於兩家公司不斷推出新技術,把 AI 助手越做越聰明、更能幫人解決問題。
這場 AI 對決的重要性
要理解這場 Gemini 與 GPT 的競爭重要性,可以想想:這不僅是兩個模型的比試,更是 Google 與 OpenAI 在人工智慧領域地位的爭奪。對你來說,也許可以比喻成兩大學霸班級互相PK,看看誰能先研發出更強的「AI大腦」。以下是這場競爭帶來的一些意義:
- 推動技術進步:競爭使得技術進步加速。正如之前所提,Gemini 的推出促使 OpenAI 也加速了他們的計畫(例如 GPT-4 加視覺功能)。反過來,OpenAI 推出更快更便宜的 GPT-4 Turbo,也可能推動 Google 在效率和模型優化上努力。兩邊競爭的結果是用戶可以更快看到新功能、更強的 AI 功能。例如,不久前我們才看到 ChatGPT 開始支援圖片分析,Gemini 又推出了更厲害的多模態和思考能力,這就像學校裡班級比賽提高每個同學的學習動力:因為對手進步,自己也要更努力。
- 降低使用門檻:競爭促使成本下降和功能普及。GPT-4 Turbo 更低的使用成本使得更多開發者和公司能負擔起強力 AI,而 Google 則把 Gemini 能力整合到免費的 Google 服務上(如手機免費使用 Gemini、Search 改善等)。長遠來看,這代表將來我們每個人都能用到更聰明、更能讀懂圖文、並且對話更自然的 AI 助手,以後寫報告、查資料或學習新知識時,可能都能得到這些 AI 更好的幫助。
- 考驗 AI 的安全與倫理:兩大公司都強調要負責任地發展 AI。Gemini 推出時 Google 說他們「安全優先」,進行了大量測試;OpenAI 也在聽取用戶反饋和進行内部安全調整(例如定期更新模型行為),這對我們來說也是個提醒:AI 很強,但怎麼使用它、避免濫用是很重要的話題。當使用 ChatGPT 或 Gemini 幫忙寫作、學習時,要有思辨,不盡然把 LLM 提供的答案全盤接受,也要防範偏見或錯誤。
- 推動教育與工作改變:AI 對決意味著未來更多智慧工具進入教育與職場。例如,如果未來 Gemini 能幫學生更好地理解教材,或 GPT-4 Turbo 幫老師批改作文,學習方式可能大大改變。對高中生來說,這場競爭可能導致你的「數位同學」越來越強,學習過程變得更互動、更客製化。理解背後的技術和差異,可以幫助你更好地利用這些工具,成為更優秀的人。
結語
總結來說,Google 的 Gemini 系列和 OpenAI 的 GPT 代表了當前最前沿的 AI 技術,Gemini 強調從一開始就能處理多種資料(文字、圖片、音訊、影片),並採用專家混合結構和超長上下文,使它在理解與推理複雜問題時具備優勢。
而 GPT-4 Turbo 則強調成本效率、速度和指令遵從,並持續加入新功能(如視覺和語音輸出),但對於你我而言,了解這些技術原理,並不能只停留在科幻印象,而是要認識到背後的工作原理,例如 Transformer 模型就像能同時關注每個詞的超強大腦,MoE 就像分派不同專家幫忙解題的團隊,對MoE 有興趣的朋友可以參考我這篇《DeepSeek 的 MoE 架構:低算力下的大語言模型高效訓練技術》。
知道了這些,你就能更好地看出兩款 AI 彼此的差異,以及各自能做什麼,才能在使用它們時更加得心應手。
參考文獻
- Google DeepMind, & Google Research. (2024). LearnLM: Improving Gemini for learning.
- Auer, A., Linsbauer, L., & Grünbacher, P. (2024). Generative language models: Potential for requirement engineering applications. arXiv preprint arXiv:2403.10745.
- Almuhaideb, A. M. (2023). Large language models as computational linguistics tools: A comparative study between GPT-4 and Google Translate. International Journal of Arabic-English Studies (IJAES), 23(2), 139–166.
要深入了解 AI 產品經理的基本職責和角色,請參考我的詳細指南:AI 產品經理,我的學習方法