ChatGPT search 上線啦!資料來源只會有一個按鈕,點擊之後會在右側出現資料來源的列表,和我當初想的不太一樣,我以為是在文章底下,會出現資料來源網站一個一個列出來,因為這將會大大的影響到網站的流量。
搜尋市場現況:誰在改寫搜尋生態?
根據 Moz 的共同創辦人和執行長 Rand Fishkin 在 threads 的圖來看,我覺得我需要把這個資訊記錄下來,等幾年後再回頭來看看,資料、圖片來源均來自於 Rand Fishkin 的貼文。
View on Threads
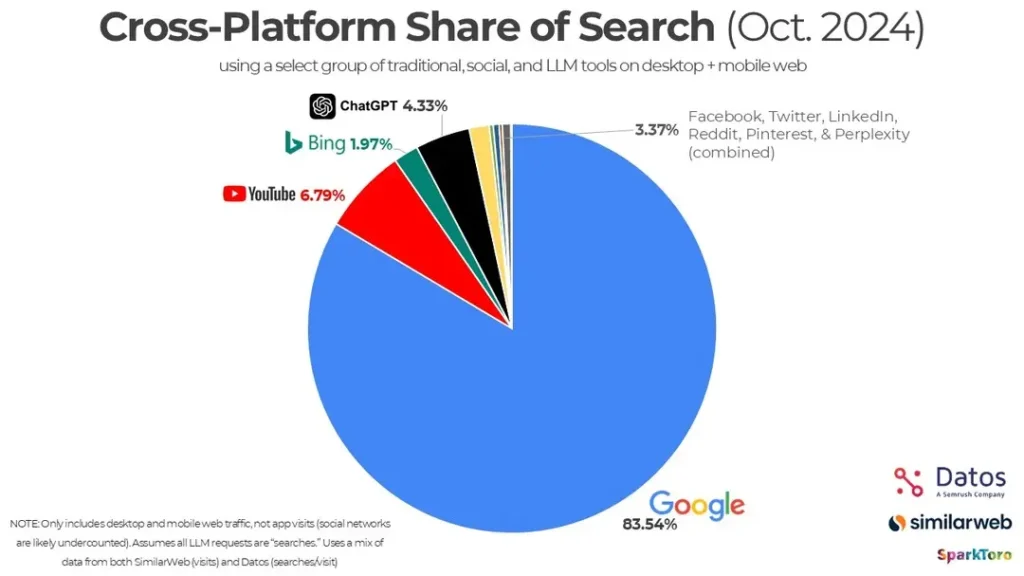
主要發現與細節
- Google 持續穩居搜尋霸主地位:
- Google 以 83.54% 的市佔率遙遙領先其他平台,清楚反映搜尋市場上的壓倒性優勢。Google 之所以能穩居第一,主要是因為廣大的用戶基礎、成熟的搜尋技術,以及廣告生態系的高度成功。
- YouTube 佔穩腳步:
- 就和全球空軍戰力世界第一是美國空軍,而全球空軍戰力第二,則是美國海軍的意思一樣,世界第二大搜尋引擎是 YouTube,它的市佔率達 6.79%,這也反映出使用者對視覺內容的需求不斷增加,尤其是對教學影片、娛樂內容和實用資訊的搜尋依賴。
- AI 搜尋工具的崛起(如 ChatGPT):
- ChatGPT 佔了 4.33% 的市場佔有率,代表 AI 驅動的搜尋工具正快速受到使用者歡迎,這類工具的優勢在於能夠即時提供答案、個性化回應,以及減少繁瑣的搜尋過程。
- 傳統搜尋引擎的影響力下滑:
- Bing 的市場佔有率僅剩 1.97%,顯示微軟的搜尋引擎在市場競爭中仍難以匹敵 Google,這也代表傳統搜尋模式的影響力正在逐漸減弱。
- 社群媒體在搜尋上的角色:
- Facebook、Twitter、LinkedIn、Reddit、Pinterest 和 Perplexity 等社群平台合計佔了 3.37%,說明社群平台已成為搜尋的重要管道,尤其在新聞、社群互動和使用者產出的內容方面,影響力還是很大。
數據來源與限制
- 數據來源:
- 圖表數據結合了 SimilarWeb(流量數據)與 Datos(搜尋次數)的統計。
- SparkToro 提供補充分析,進一步完善數據可信度。
- 數據限制:
- 此數據僅涵蓋桌面與行動網路的流量,不包括APP內的搜尋,因此可能低估像 Facebook、Reddit 等社群平台的實際影響力。
- 這是假設所有大型語言模型(例如:ChatGPT)處理的問題都被視為「搜尋」,這有可能略微高估 AI 工具在搜尋市場的佔有率。
ChatGPT Search 也有一個搜尋爬蟲,名字是 OAI-SearchBot
OAI-SearchBot 專門用於 ChatGPT Search 的抓取,而不是給 AI 作為訓練集之用的,它的主要任務是爬取網頁並提供即時的搜尋結果,以便在 SearchGPT裡顯示相關連結及內容,類似於一般的搜尋引擎爬蟲。
而 OpenAI表示,OAI-SearchBot 所收集的內容不會用於訓練 OpenAI 的生成式 AI 基礎模型,也就是說,這些內容僅用於搜索和展示用途,不會進入模型訓練的語料庫中,不過這一點,我個人是完全不相信的。
作為一個搜尋引擎,我認為 OpenAI 以「OAI-SearchBot 不會用於訓練生成式 AI 基礎模型」的說法來撇清關係可能性相當高,因為其中確實存在一些值得推敲的灰色地帶。
為什麼 OpenAI 可能會這樣說?
避免法律和道德爭議啊! 使用網路爬蟲抓取大量數據來訓練 AI 模型,一直以來都存在著作權和隱私權的疑慮,OpenAI 藉由強調 OAI-SearchBot 僅用於搜尋功能,可以避免捲入這類爭議,降低法律風險。
另一方面,是要維持使用者的信任,許多人擔心自己的創作或個人資訊會被 AI 模型擅自使用,而OpenAI 這樣的說法,想透過明確區分爬蟲的用途,可以提升人們對OpenAI服務的信任度,減少不必要的擔憂。
而在商業上,OpenAI 也希望將 ChatGPT Search 定位成一個中立、客觀的搜尋引擎,所以,強調 OAI-SearchBot 不參與模型訓練,可以強化這種形象,吸引更多使用者。
而且,OpenAI 並未明確界定「生成式 AI 基礎模型」的範圍,也許 OAI-SearchBot 收集的數據,不會用於訓練 GPT 等大型語言模型,但有可能用於訓練其他與搜尋相關的 AI 模型,例如搜尋排序、資訊抽取、問答系統等等。
就好比你去銀行開戶,總有一個選項,要你打勾,意思就是把你的資料給銀行其他子公司行銷之用。
所以啊,站在搜尋引擎的立場,我認為 OpenAI 的做法可以理解,搜尋引擎需要在提供優質服務的同時,兼顧法律、道德和商業等多方面的考量。
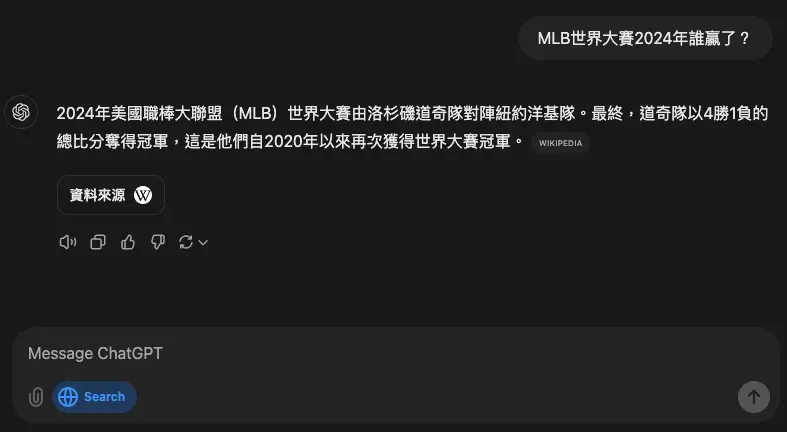
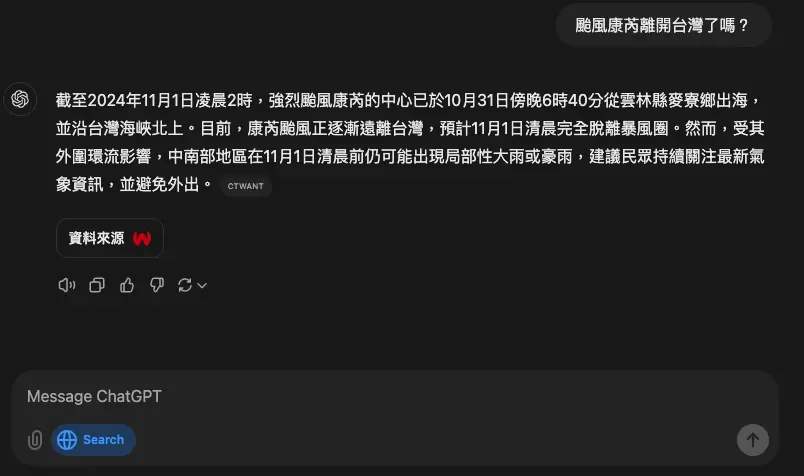
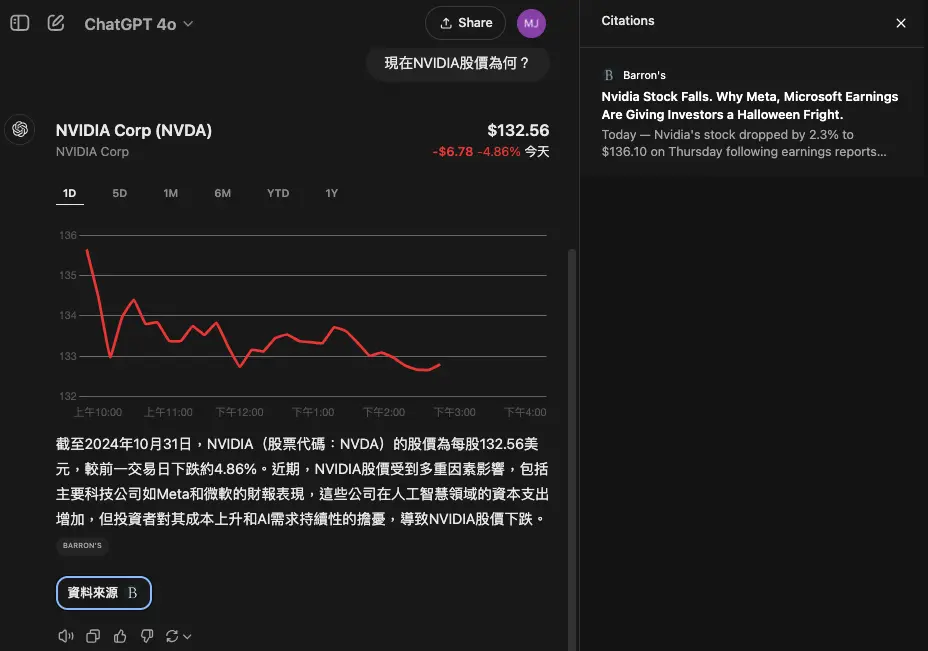
ChatGPT search可以問新聞、運動、股票和天氣
ChatGPT search 現在可以提供即時數據,包括新聞、運動、股票和天氣等等。
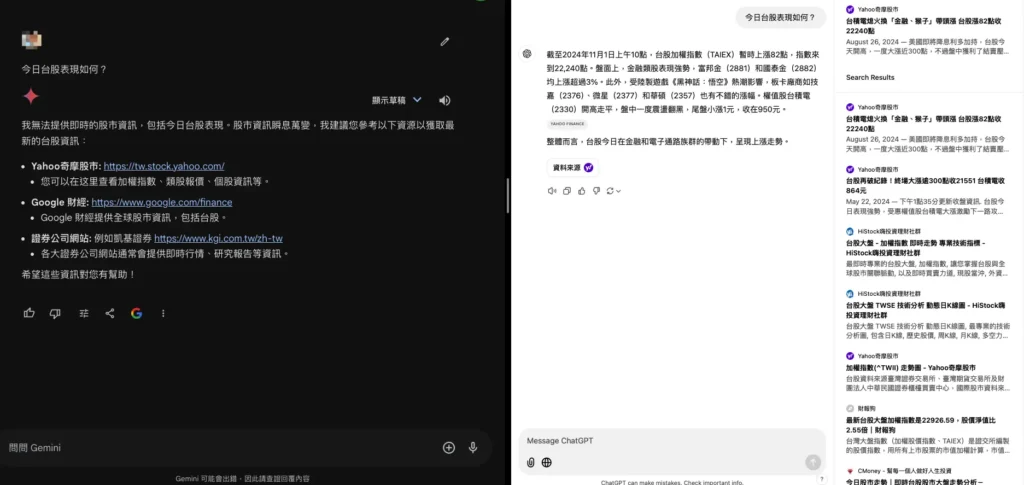
最好先在GPT-4o模型上使用ChatGPT search
我以為搜尋功能只能在比較新的GPT-4o版本來運作,但我在左上角把模型調成GPT-4,它依然可以進行搜尋,不過無論是GPT-4o或是GPT-4,回答比較新的問題還是怪怪的。
目前初次使用的感覺,搜尋結果的回應時間與目前的搜尋引擎相似,幾分秒內就可以獲得搜尋結果。

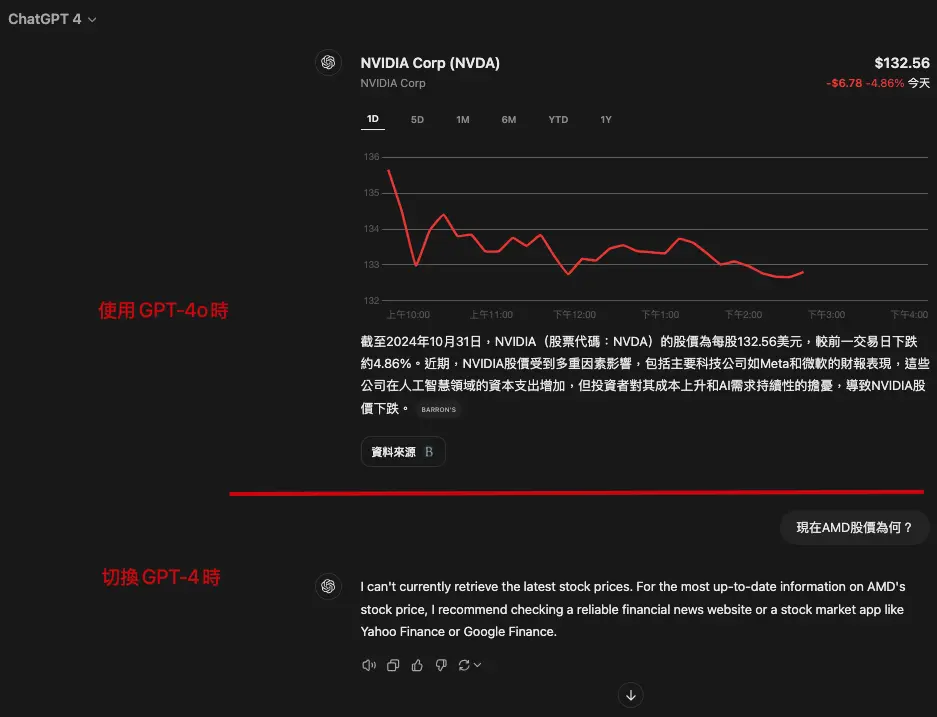
ChatGPT search 把資料來源區分為兩塊
Citations(引用):這部分看起來是回覆過的來源資料,也就是把來源內容中引用過的資料丟到對話當中,但我比對了一下ChatGPT search是也沒有把整段內容「照抄」啦。
Search Results(搜尋結果):這部分是提供搜尋相關的其他結果,讓使用者可以看到更多相關的資料來源,但這些資料來源可能還沒有被引用。
這種區分有助於提高資訊的透明度和可追溯性,讓使用者更容易檢查引用的內容和找到更多相關資訊。
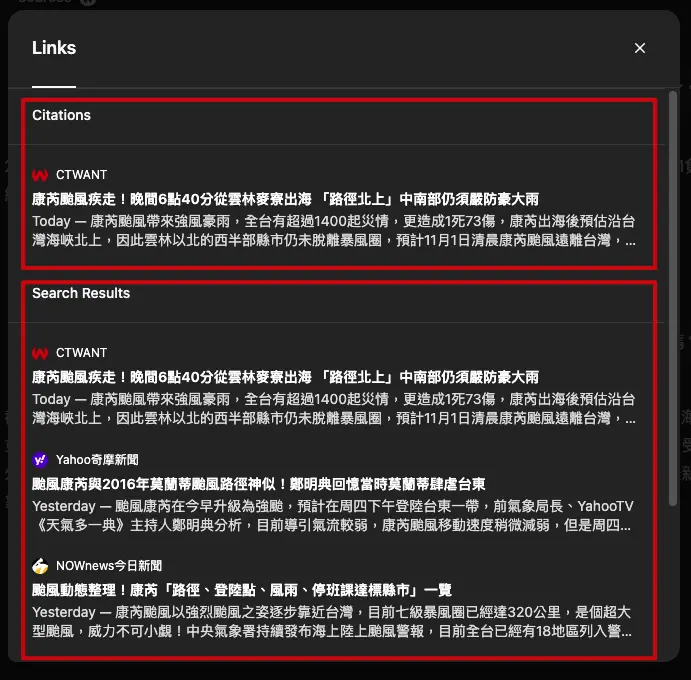
ChatGPT search 和 Google Gemini
目前我個人的「體感」上,覺得Google Gemini提供的搜尋結果是比較「舒服」的,但它沒有「直接」提供資料來源(你要按下方小小的 Google icon ),總不能因為它是 Google 我就不會去反查資料正確性吧?
而在 ChatGPT search 這邊的話,會覺得他提供的資料比較「完整」,但是有一種感覺是 ChatGPT search 的搜尋結果文字內容,是很生硬的把這些資料讀完再丟出來的文字。
ChatGPT、Google Gemini、Microsoft Copilot確認已經把AI和搜尋這兩件事要努力合併,而Meta的爬蟲數量不到世界前十名,能用的資料只有月活躍的40億用戶所產出在平台內部的UGC內容,我真的蠻好奇,我們用What’s APP或是IG的對話,是可以呈現出什麼樣的搜尋結果出來。
SEO 是什麼?請參考我的筆記:SEO筆記|產品經理的SEO學習歷程